
Alteryx Designerのチュートリアルを全部試してみた #alteryx #15 | Alteryx Advent Calendar 2016
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは。DI部 三上です。
当エントリは『Alteryx Advent Calendar 2016』の15日目のエントリです。
Alteryx Designerをさわってみました!
はじめに
三上@当エントリ執筆者のSpec:「Alteryxって、何ですか?」(あせ
・・・。
→まずはお勉強をば。。
- データブレンディング&予測分析ツール『Alteryx』の米国:Alteryx社とのパートナーシップ締結に関するお知らせ
- Alteryxで何が出来るのか – 実行可能タスク全197種 概要紹介&リファレンスまとめ #alteryx
- 『Tableauとのデータブレンディングを高速化するAlteryxの6つ(+α)のステップ』を読んでみた
→なにやらいろいろできそう@@!
習うより慣れろ!
で、チュートリアル、やってみました。
やってみよう
動作環境
- OS:Windows 10(Mac Sierra(10.12.1) VMware Fusion)
- Alteryx Designer Version:10.6.8.17850
- Redshift Cluster Version:1.0.1125
Tutorial 01:データ準備
AlteryxにデータをInputします。

今回は、郵便番号データをcsvファイルから読み込んでみます。
- レコード数:約12万件
日本郵政のダウンロードページから、「全国一括」データをダウンロードしました。
Alteryxを立ち上げて、[File] > [New Workflow] > [Input Data]アイコンを配置します。
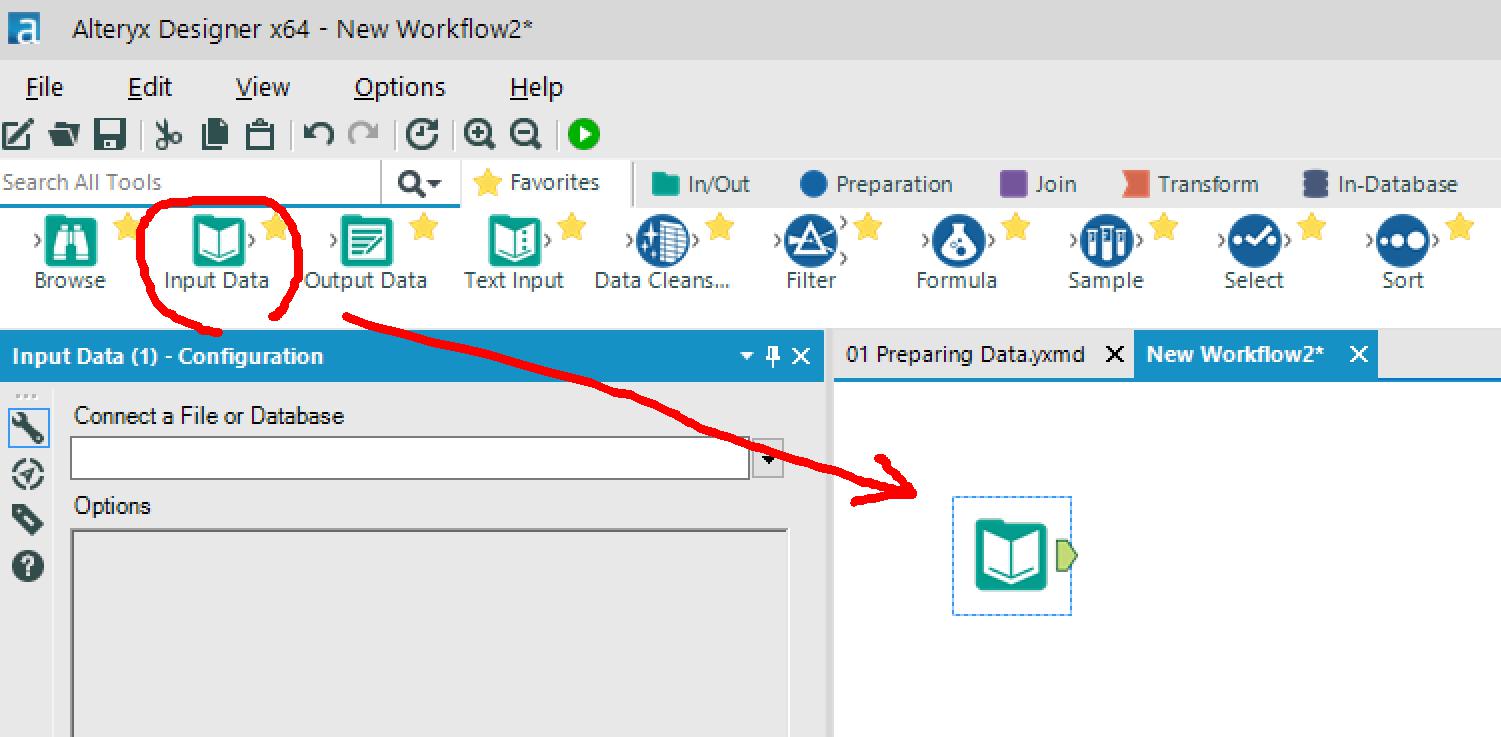
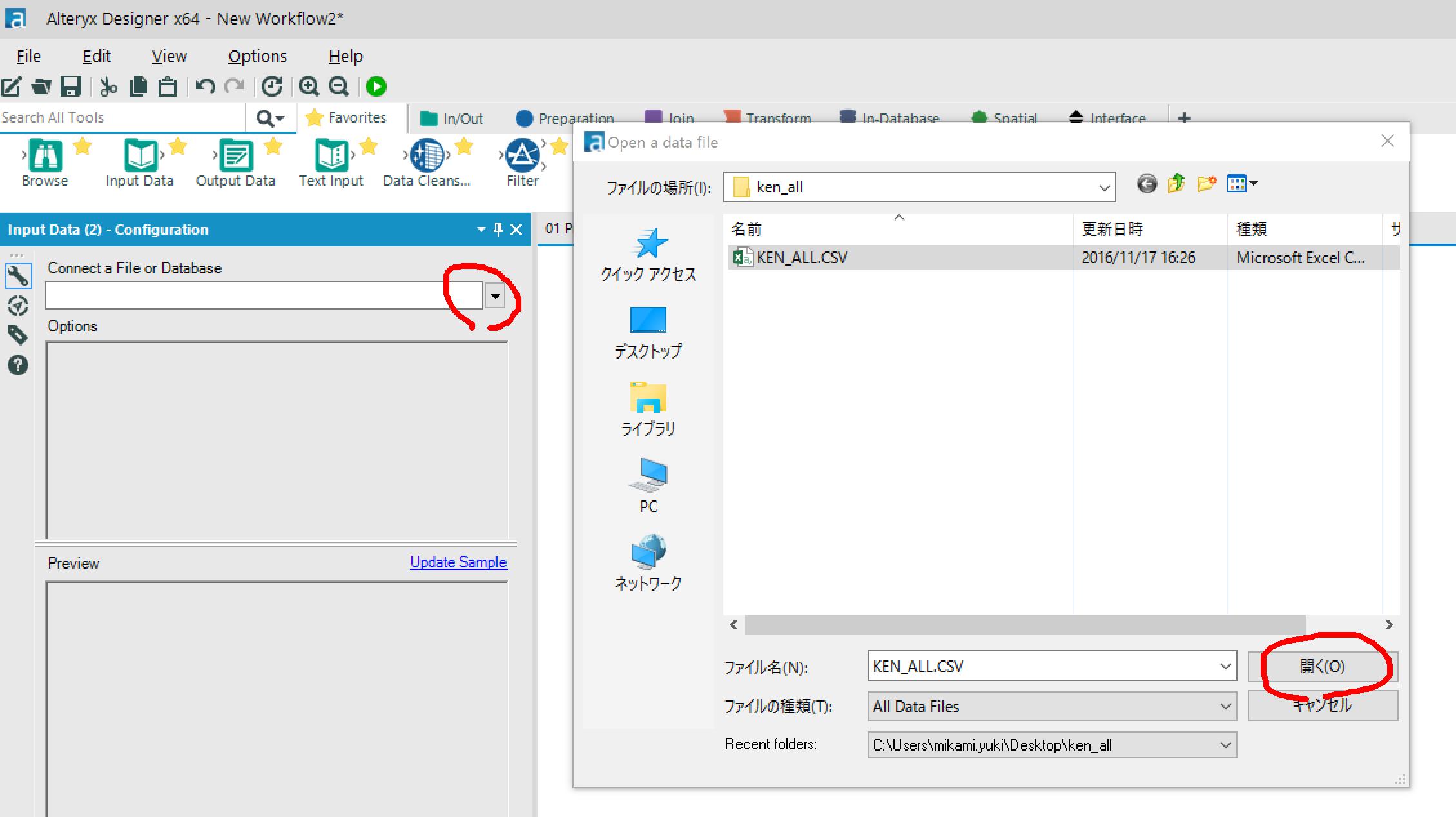
ダウンロードしておいた郵便番号のcsvを選択して開きます。
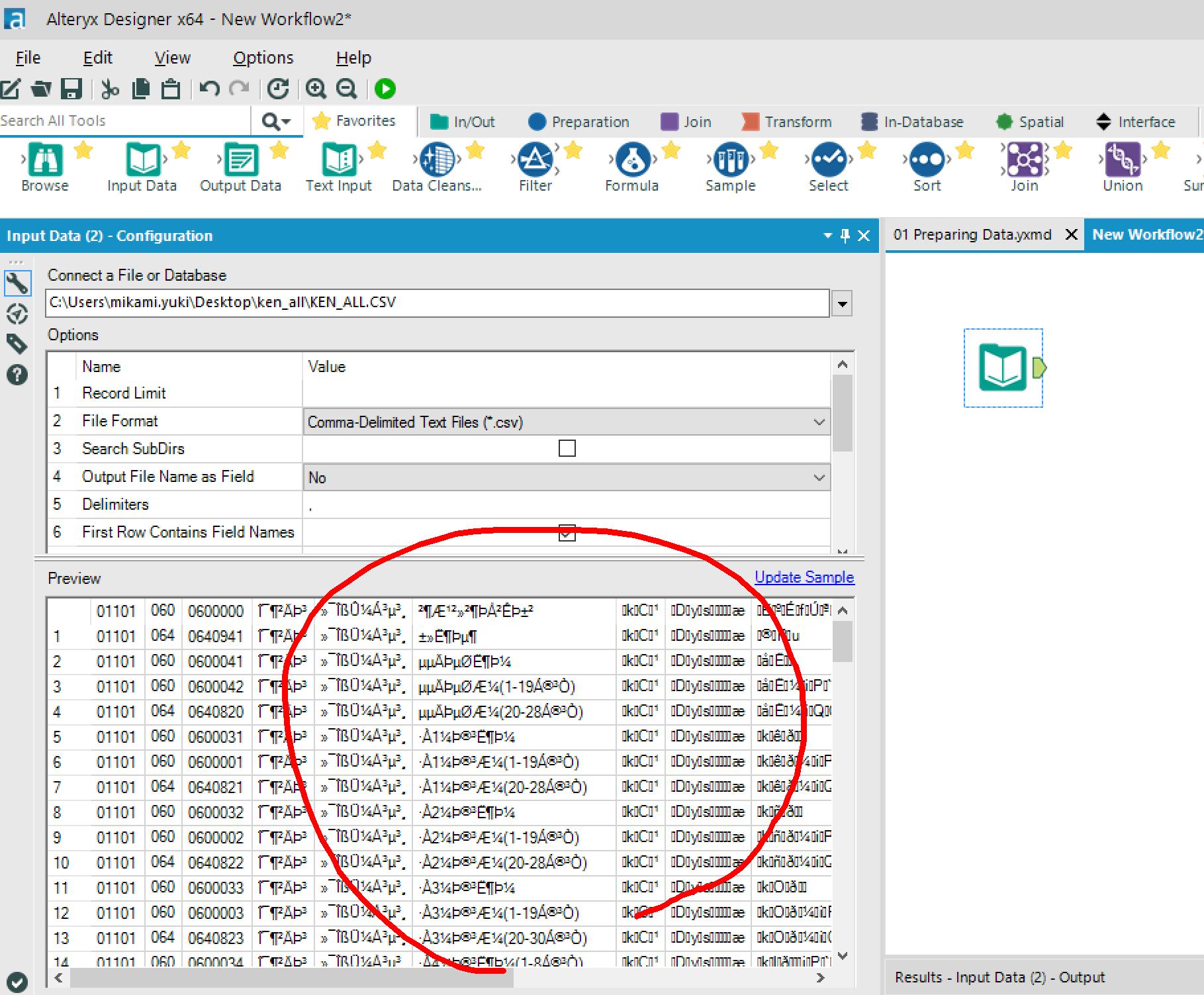
→文字化けしとる。。(S-JISですものね。。。orz
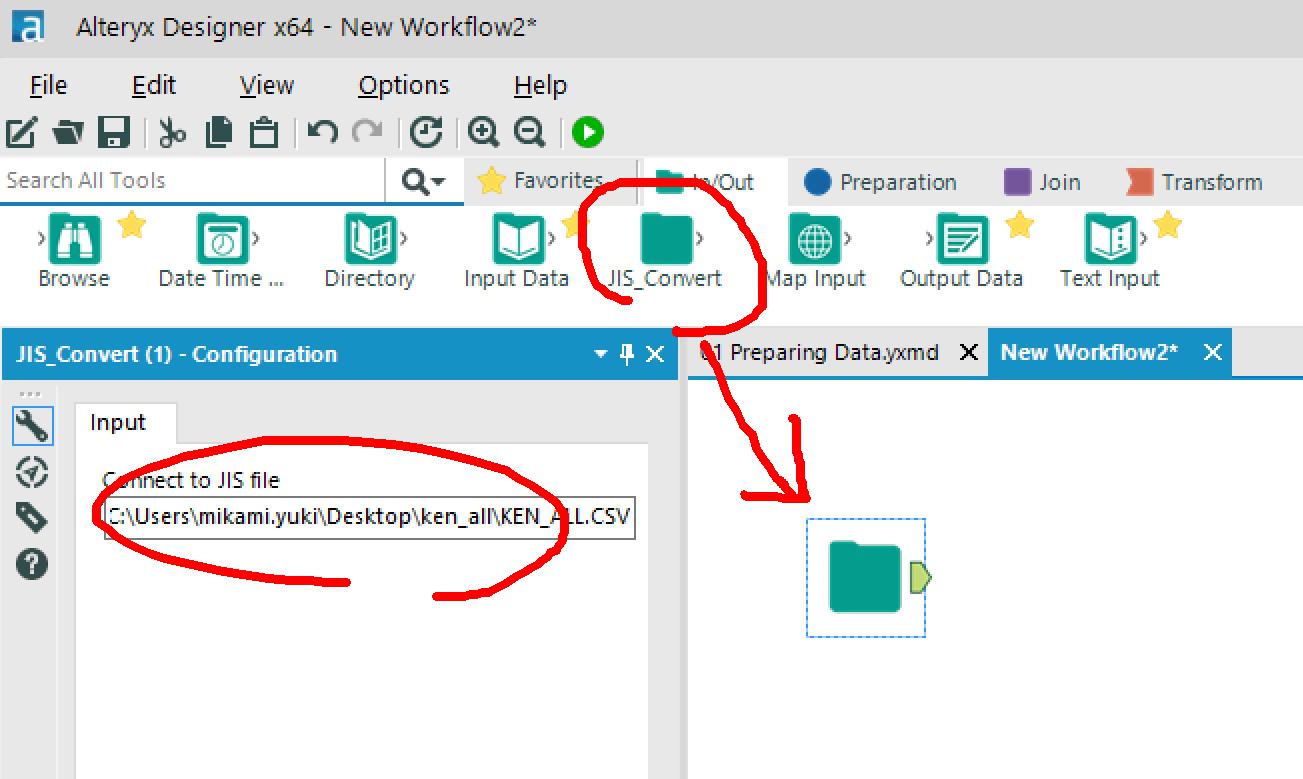
そんなときには、エンコードマクロを使います!
※マクロ展開してできた _externals\1配下のファイルを置き換えて、ツール登録しました。
→登録したマクロを配置して、Inputファイルを選択します。
→Selectをつなげます。
→実行。
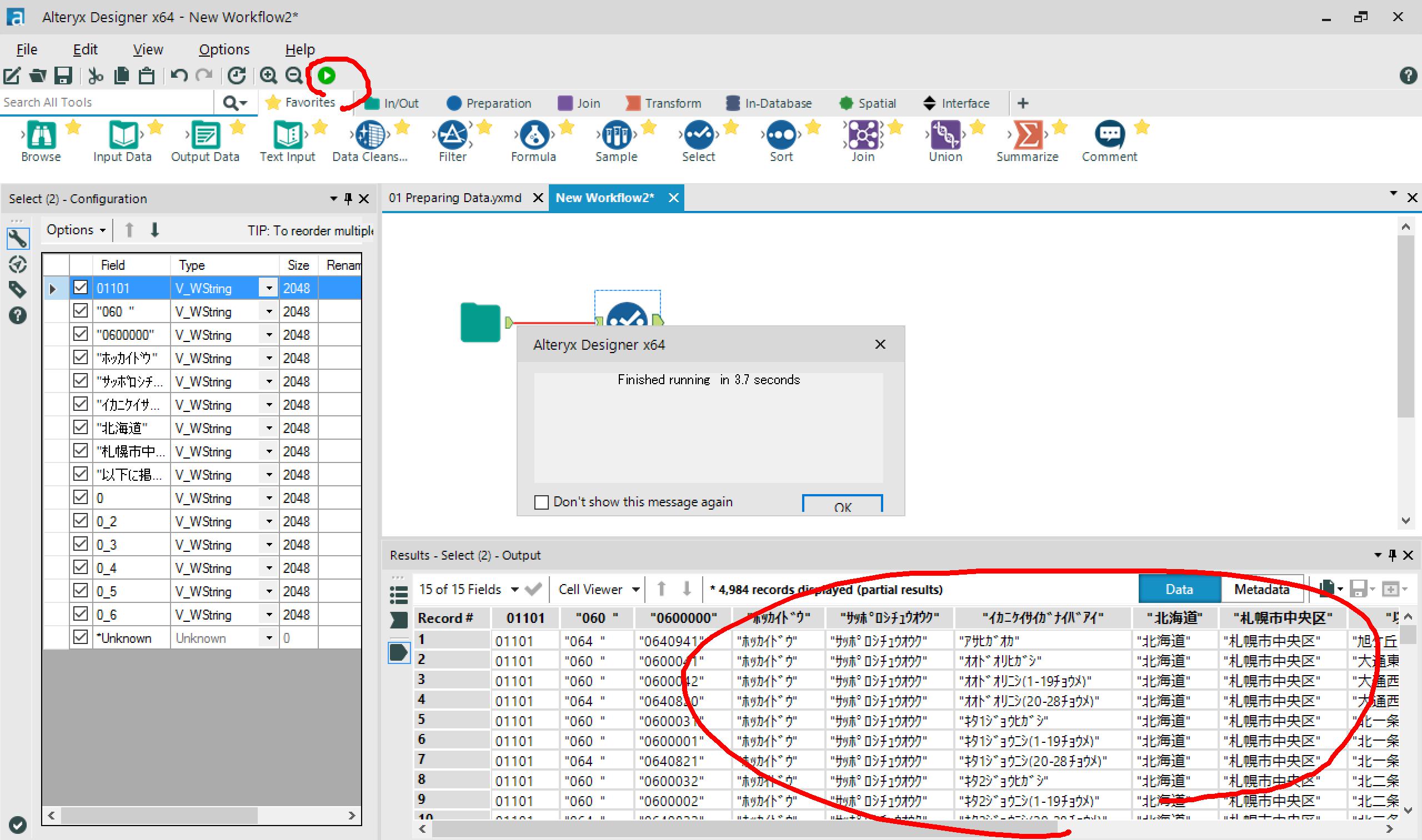
→文字化けなおったー!v
- 実行時間:3.7 sec
csvからデータをInputできました。
Tutorial 02:データをフィルタリング
データをフィルタリング&ソートします。

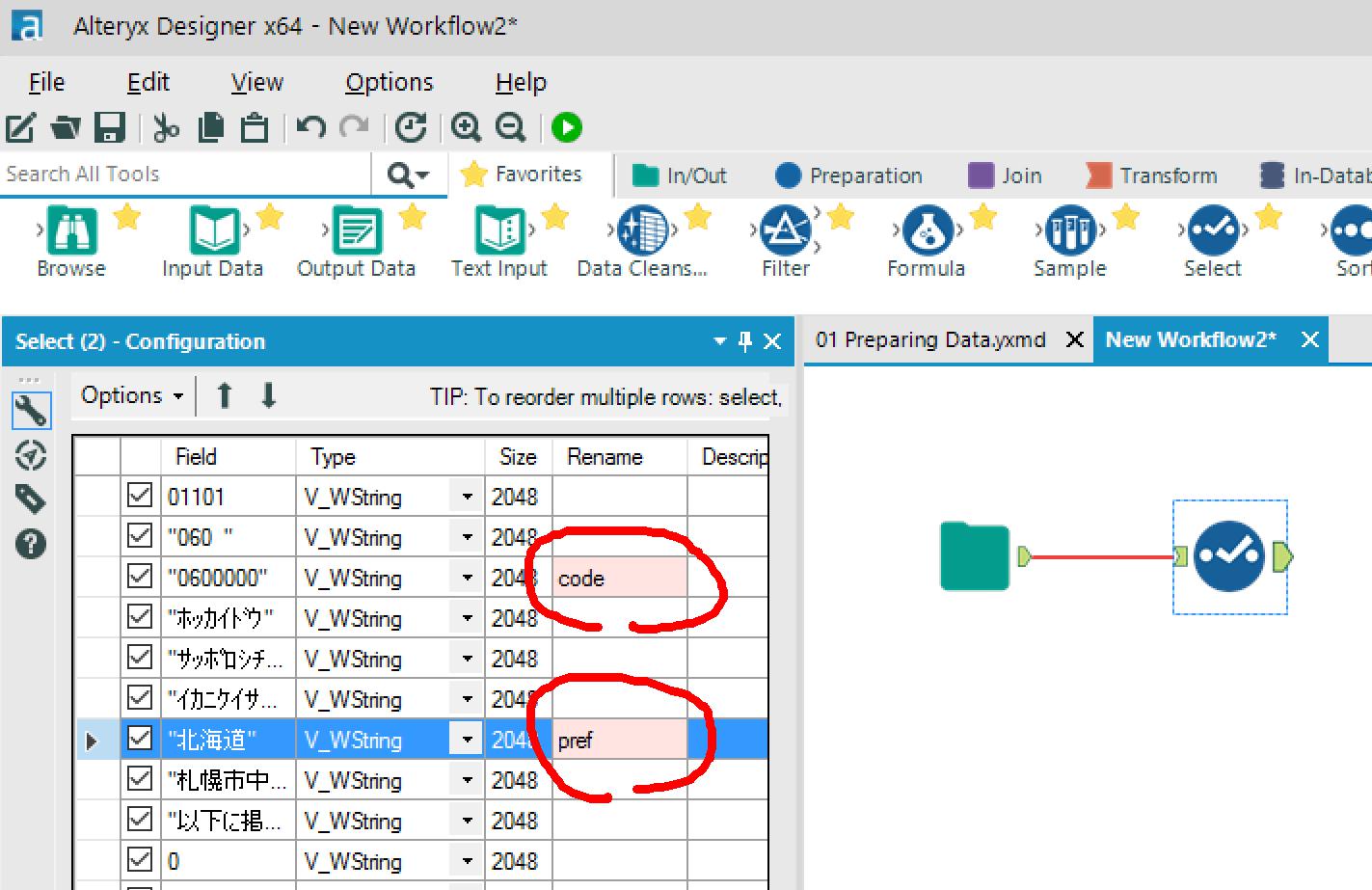
フィルタリングとソートに使用するカラム名を変更しておきます。
→Filterアイコンを配置します。
→Filter条件を設定します。
今回は、東京都のデータのみ抽出してみます。
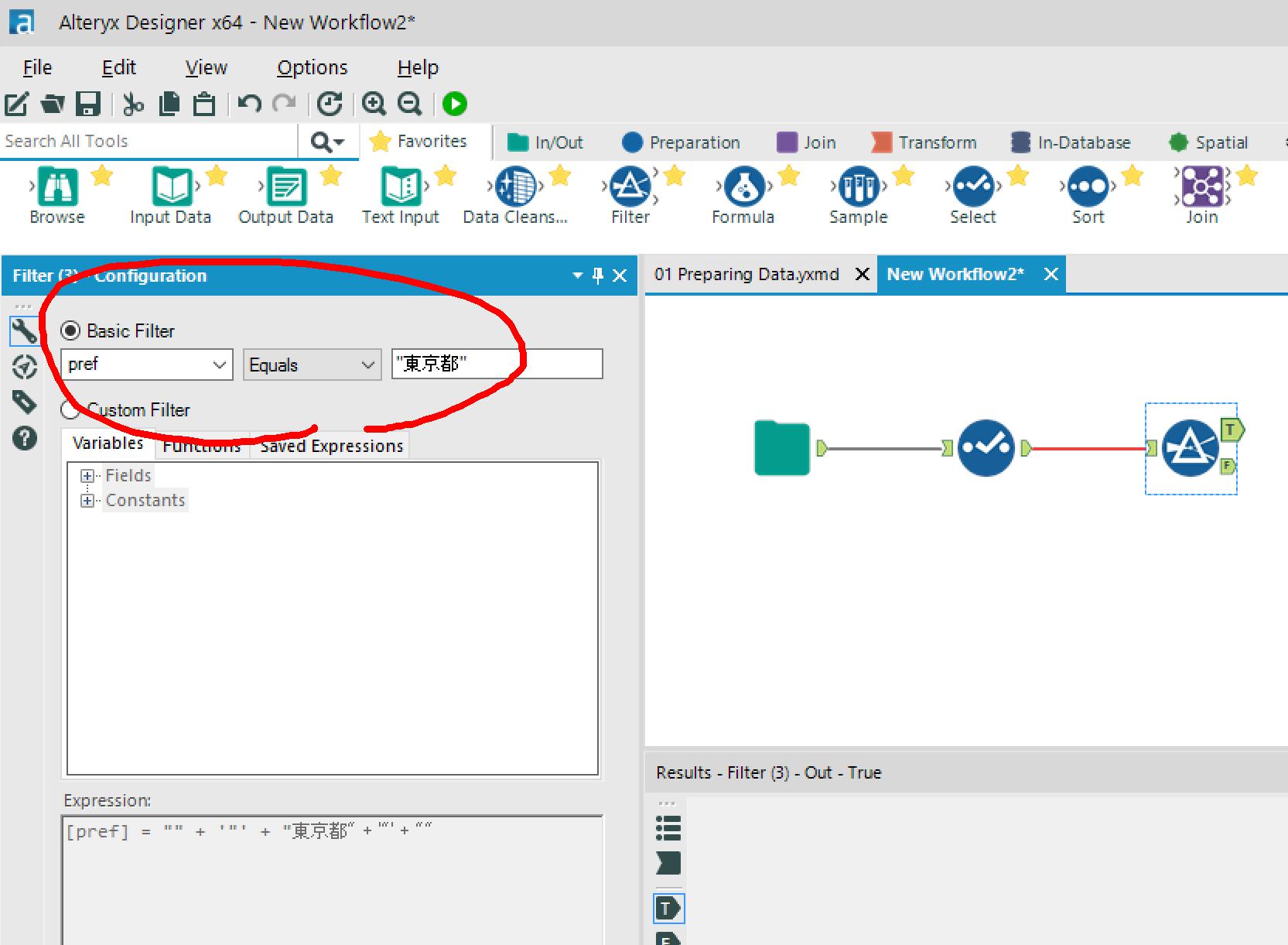
→FilterアイコンのTrueの先に、Sortアイコンを配置します。
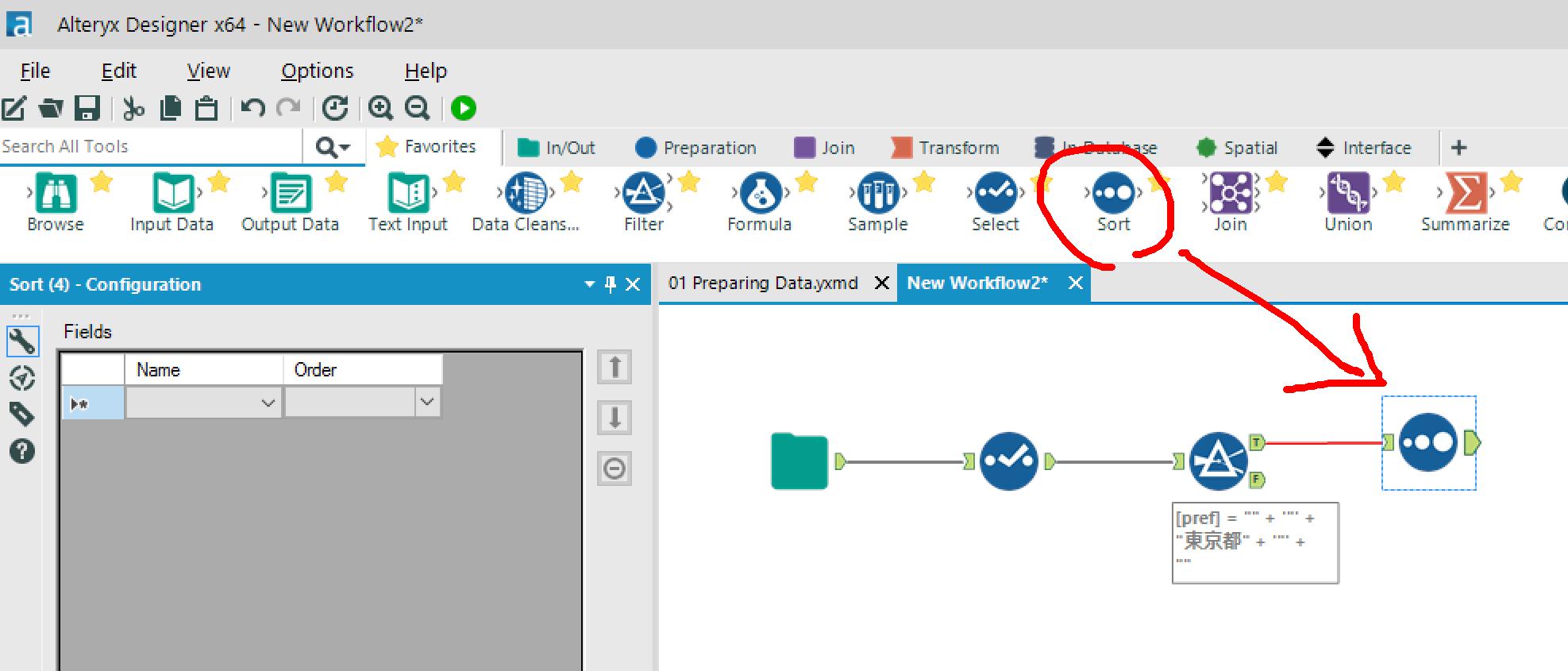
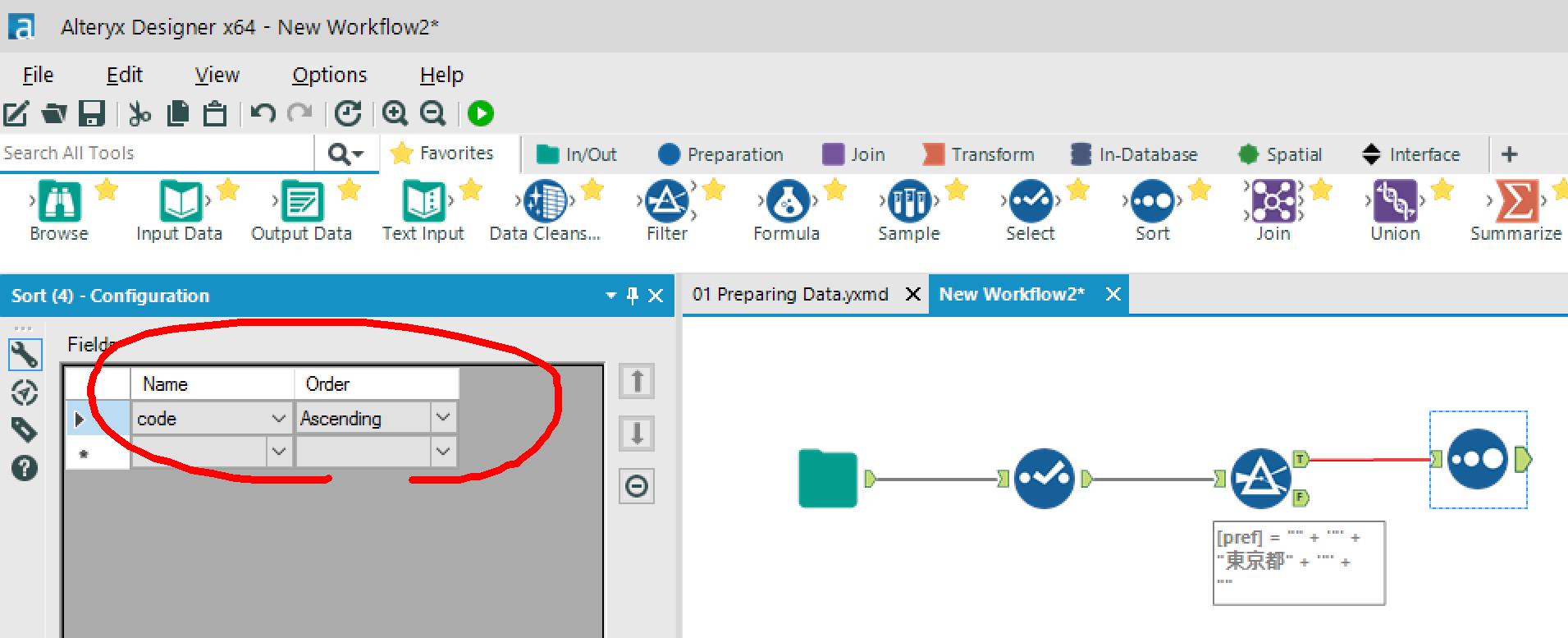
→Sort条件を設定します。
郵便番号の昇順を設定しました。
→実行。
FilterのTrueタブに、東京都のデータのみが抽出されています。
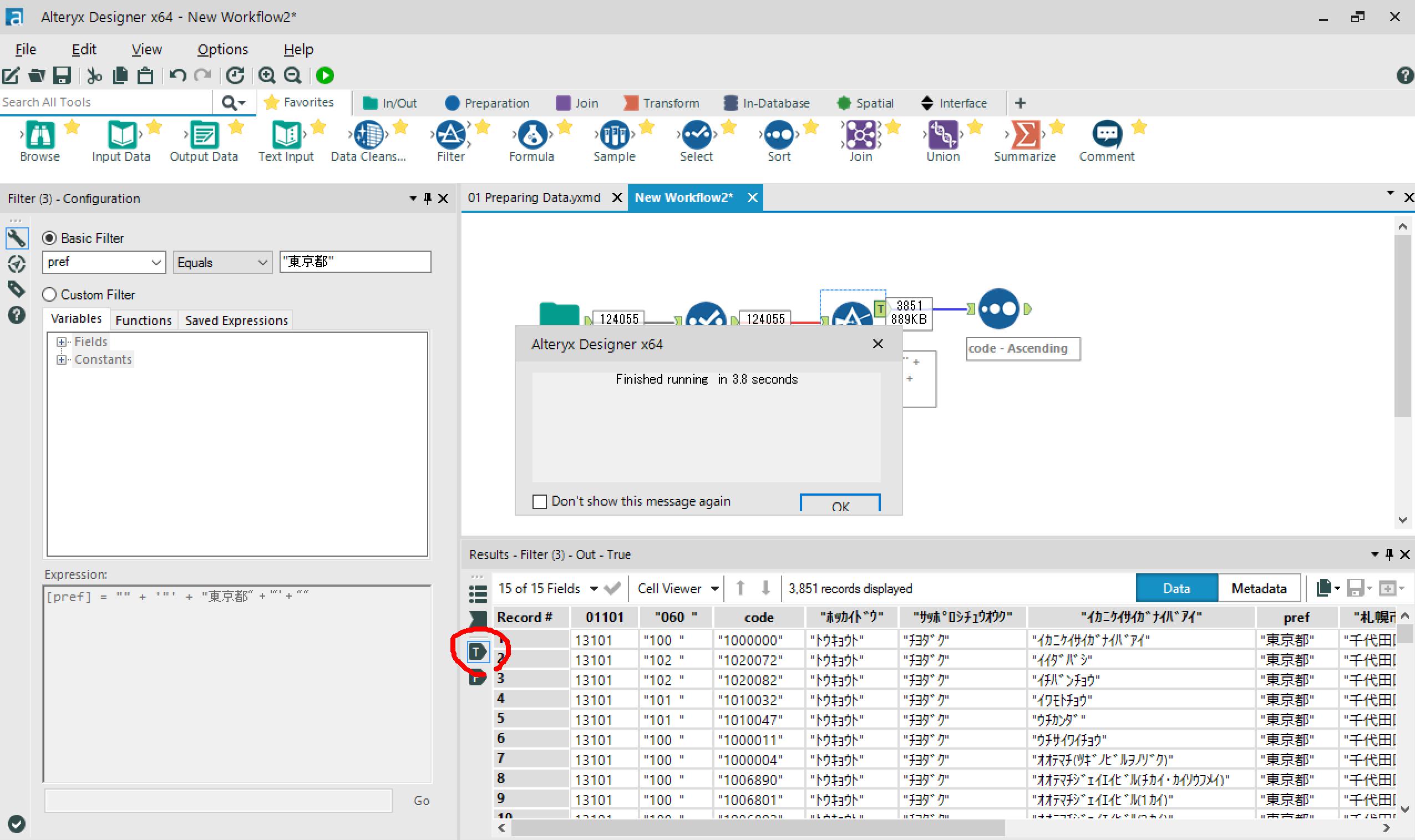
SortのOutputタブを見ると、ちゃんと郵便番号の昇順に並び替えられてます。
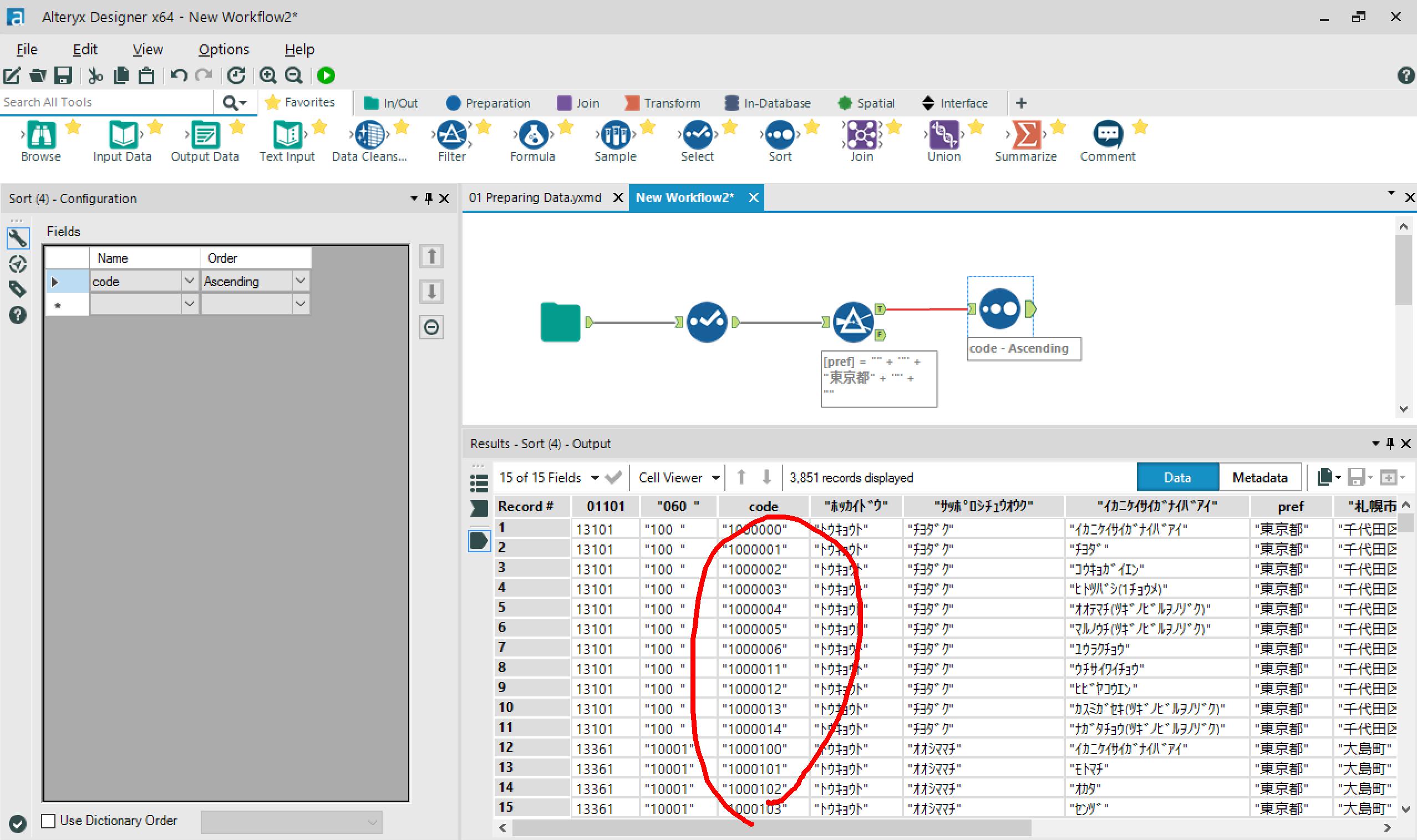
- 実行時間:3.8 sec
フィルタリングとソートができました。
Tutorial 03:データをブレンディング
別ソースのデータをブレンディングします。
今回は、郵便番号データに住所CD、都道府県CD、市区町村CD、町域CDを付与してみます。
住所.jpから、全国の住所データをダウンロードしました。
- レコード数:約15万件
郵便番号データから、郵便番号と住所情報を抽出します。
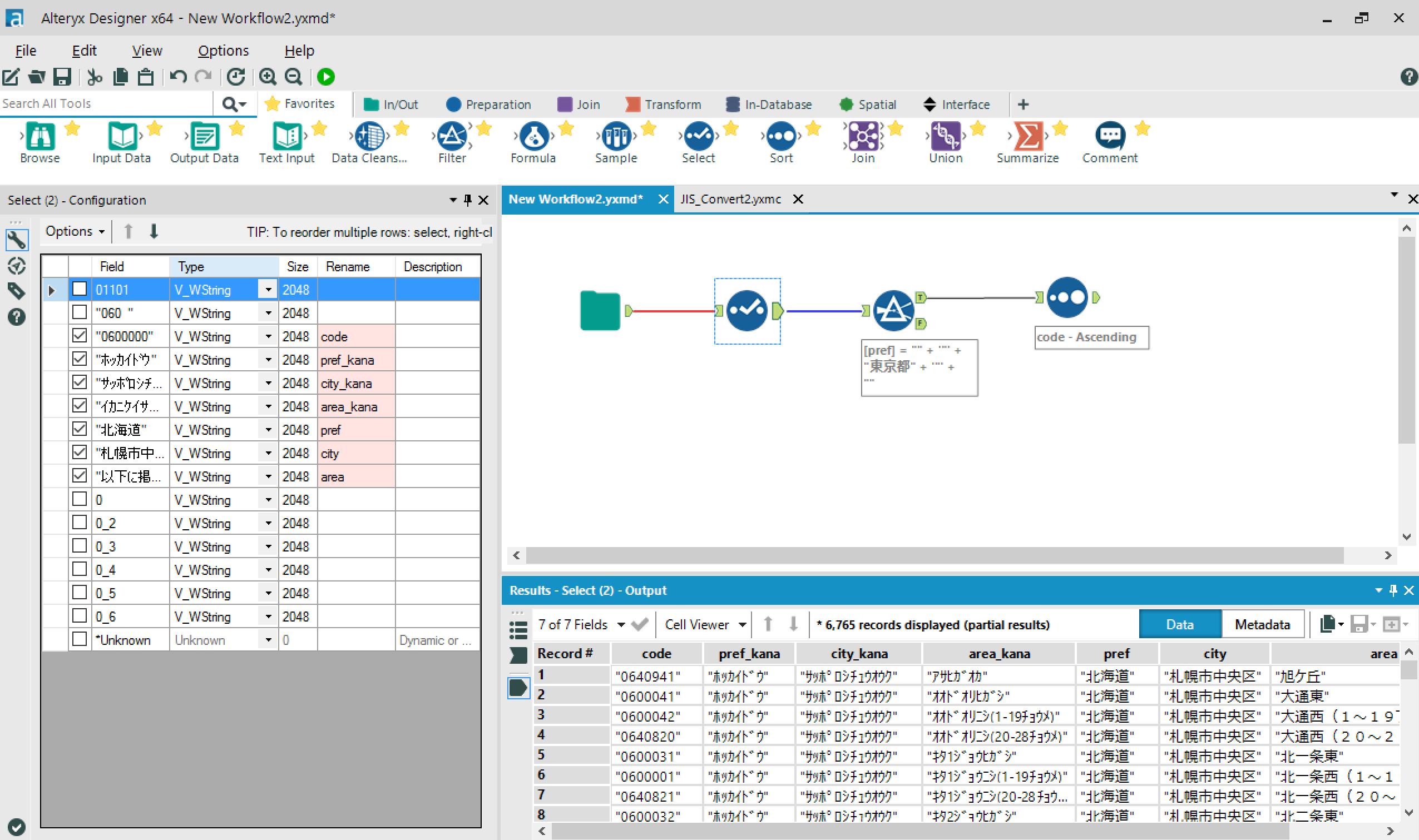
→住所データから、付与したいコードとフィルター条件に指定したいカラムを抽出します
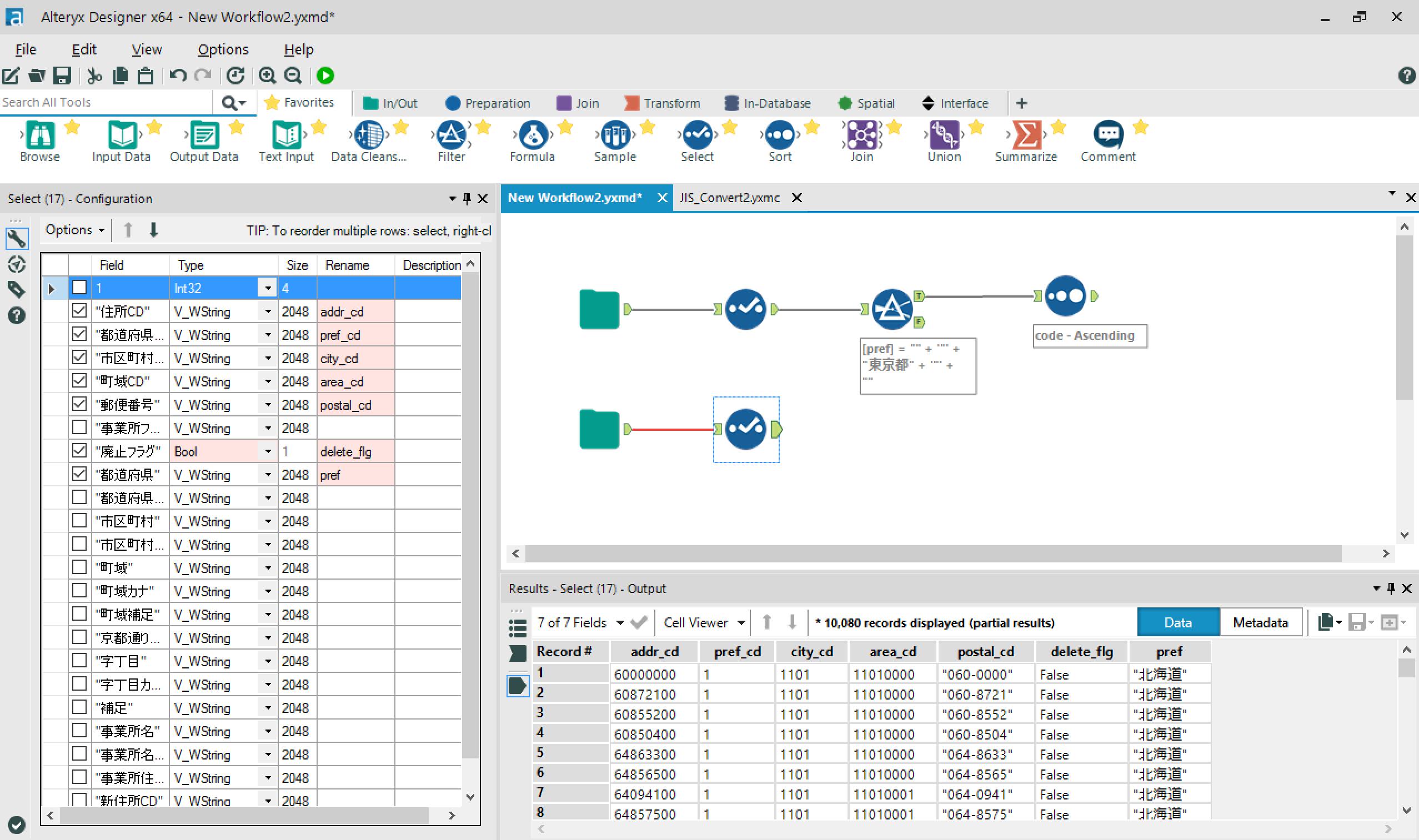
→住所データから、東京都の有効なデータをフィルタリングします。
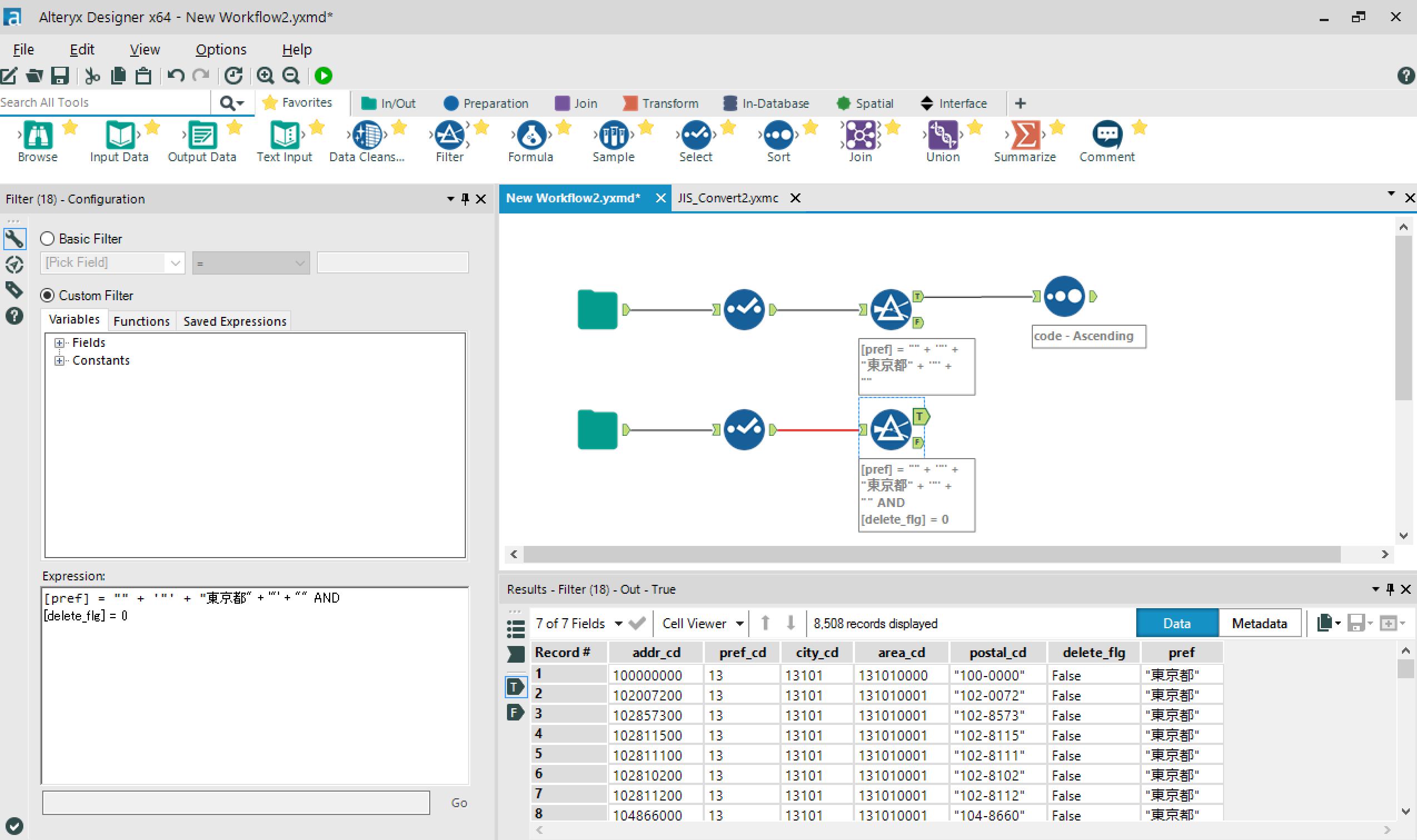
→郵便番号をキーにしてJOINしたいのですが、住所データの郵便番号にはハイフンが入っていました。。
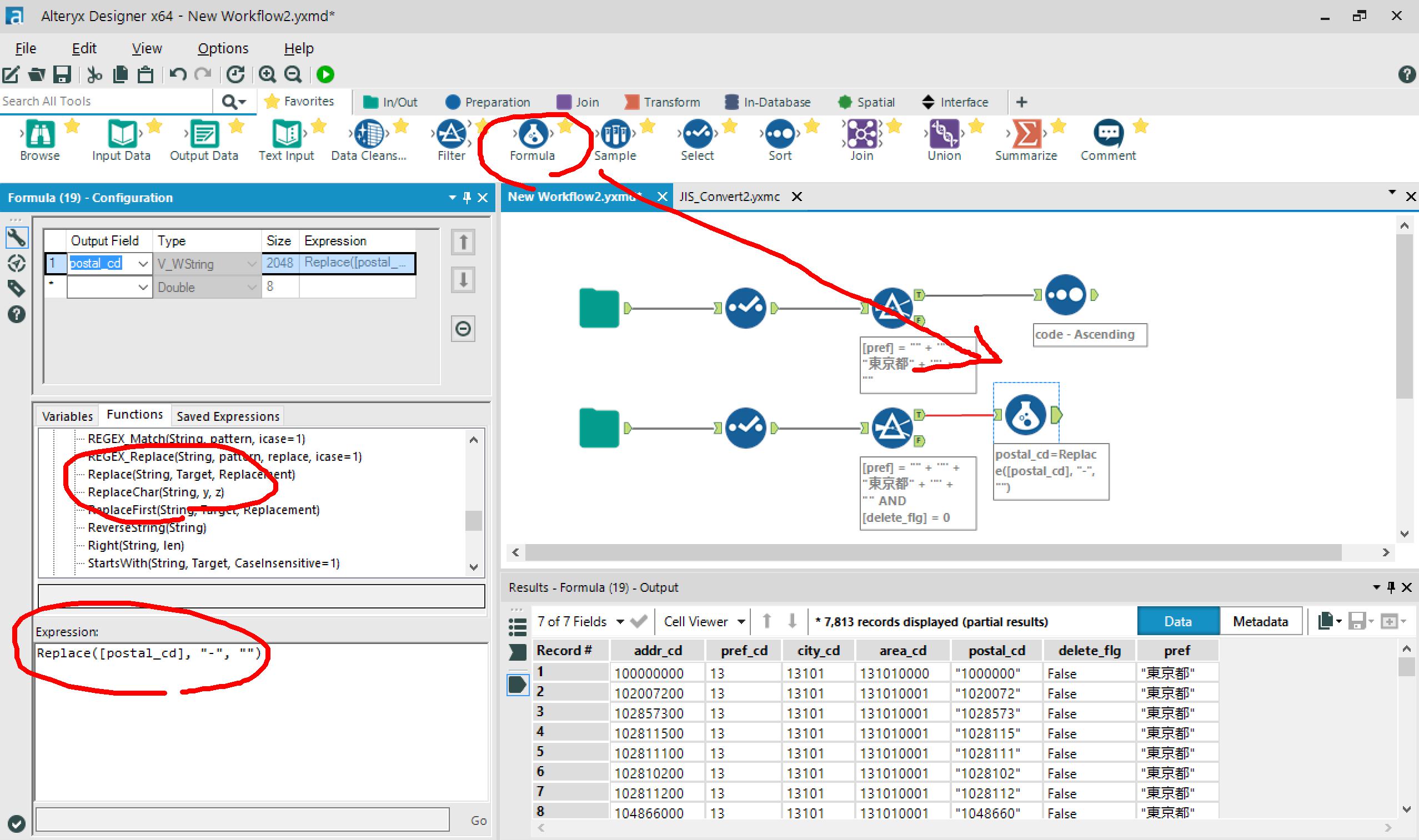
Formulaアイコンをつなげて、ハイフンを除去します。
※Formulaツールで使用できる式は、configウィンドウの「Function」タブから選択できます。
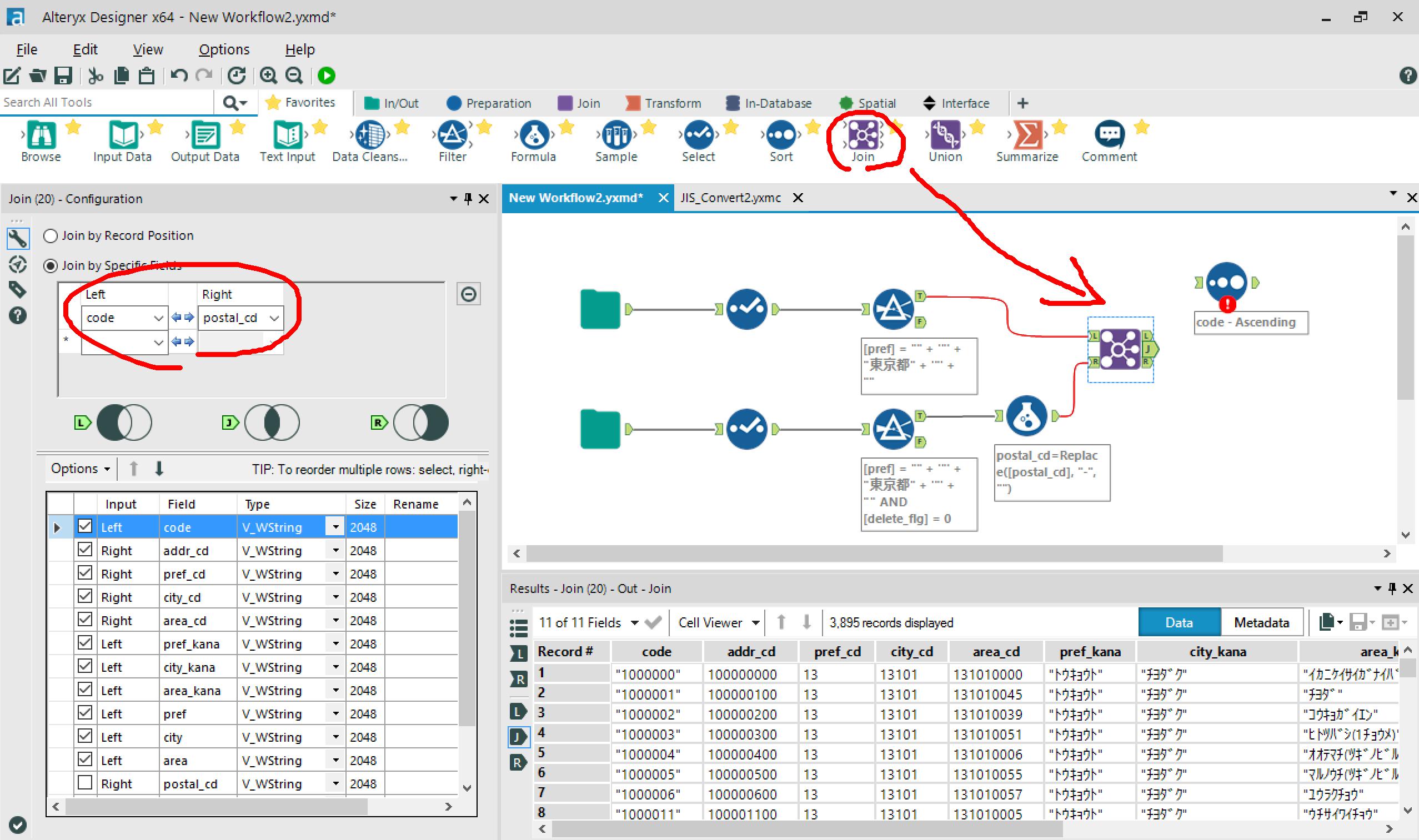
→Joinアイコンを配置して、結合条件を設定します。
→最後に、sortをつなげて、実行。
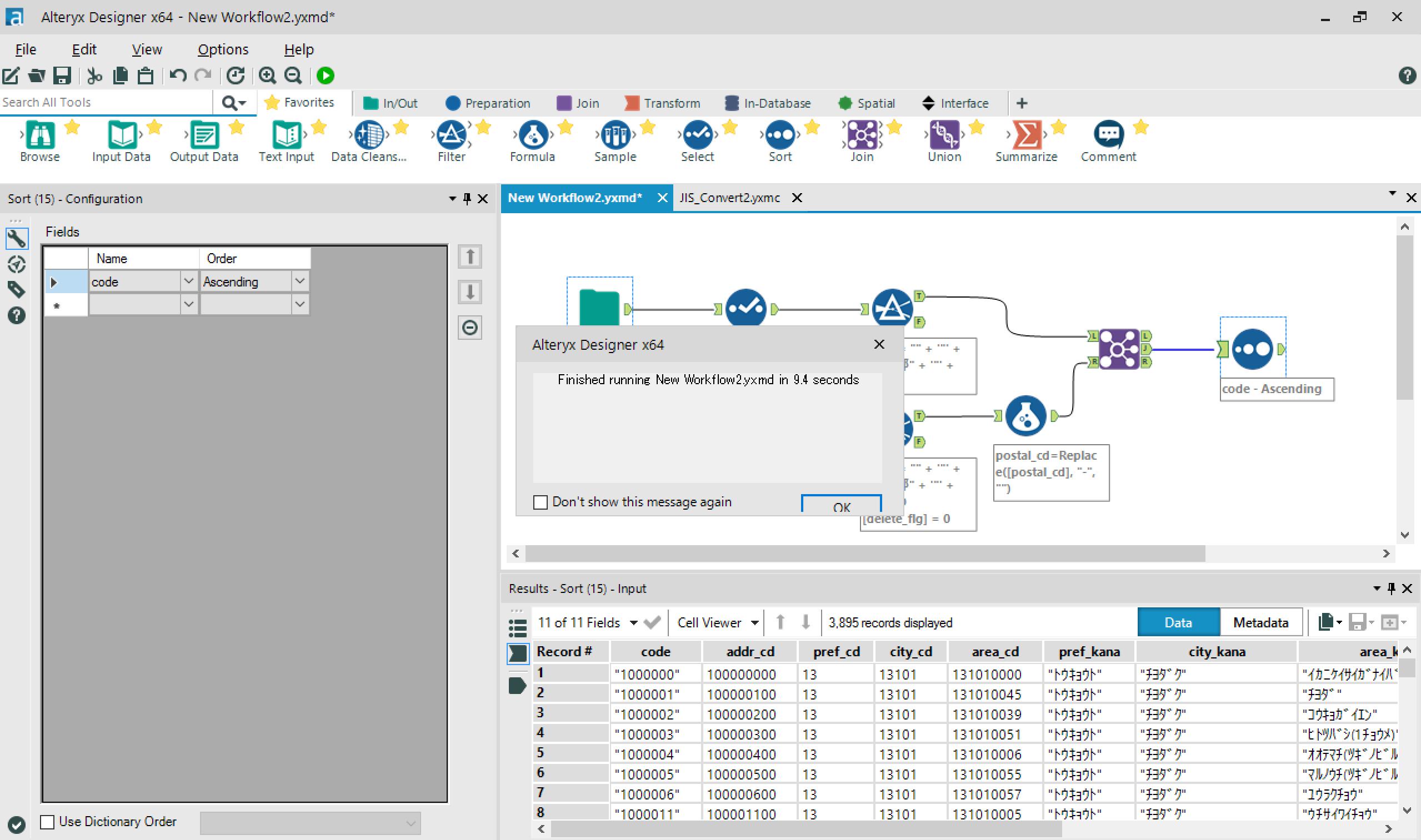
→郵便番号+住所データが取得できました!
- 実行時間:9.4 sec
※ただし、この実行時間はS-JIS→UTF8変換マクロ(β版)が占める割合が大きいと思われます。
ワークフロー実行中、それぞれのアイコンにプログレス表示が出ますが、
各マクロ実行時間が約3sec(体感)
→文字コード変換なしの場合の実行時間は3.4secほどでしょうか。
以下、個人的趣味ですが。。
RDB@MariaDB(10.1.19)からデータ抽出する場合と、実行時間を比較してみました。
- 郵便番号データをLOAD
create table m_postal_code(
id varchar(255),
code_pre varchar(255),
code varchar(255),
pref_kana varchar(255),
city_kana varchar(255),
addr_kana varchar(255),
pref varchar(255),
city varchar(255),
addr varchar(255),
col1 varchar(255),
col2 varchar(255),
col3 varchar(255),
col4 varchar(255),
col5 varchar(255),
col6 varchar(255),
PRIMARY KEY(code, addr)
);
load data local infile 'C:/Users/mikami.yuki/KEN_ALL.CSV' into table m_postal_code fields terminated by ',' enclosed by '"';
- 住所データをLOAD
create table m_addr(
addr_cd varchar(255),
pref_cd varchar(255),
city_cd varchar(255),
area_cd varchar(255),
postal_cd varchar(255),
office_cd varchar(255),
delete_flg varchar(255),
pref varchar(255),
pref_kana varchar(255),
city varchar(255),
city_kana varchar(255),
addr varchar(255),
addr_kana varchar(255),
addr_description varchar(255),
col1 varchar(255),
col2 varchar(255),
col3 varchar(255),
col4 varchar(255),
col5 varchar(255),
col6 varchar(255),
col7 varchar(255),
col8 varchar(255),
PRIMARY KEY(postal_cd, addr)
);
load data local infile 'C:/Users/mikami.yuki/zenkoku.csv' into table m_addr fields terminated by ',' enclosed by '"' ignore 1 lines;
- SQLクエリ実行
select
p.code,
a.addr_cd,
a.pref_cd,
a.city_cd,
a.area_cd,
p.pref_kana,
p.city_kana,
p.addr_kana,
p.pref,
p.city,
p.addr
from
m_postal_code p
inner join (
select
addr_cd,
pref_cd,
city_cd,
area_cd,
replace(postal_cd, "-", "") as postal_cd
from
m_addr
where
delete_flg = "0"
and pref = "東京都"
) a
on p.code = a.postal_cd
where
pref = "東京都"
order by p.code
;
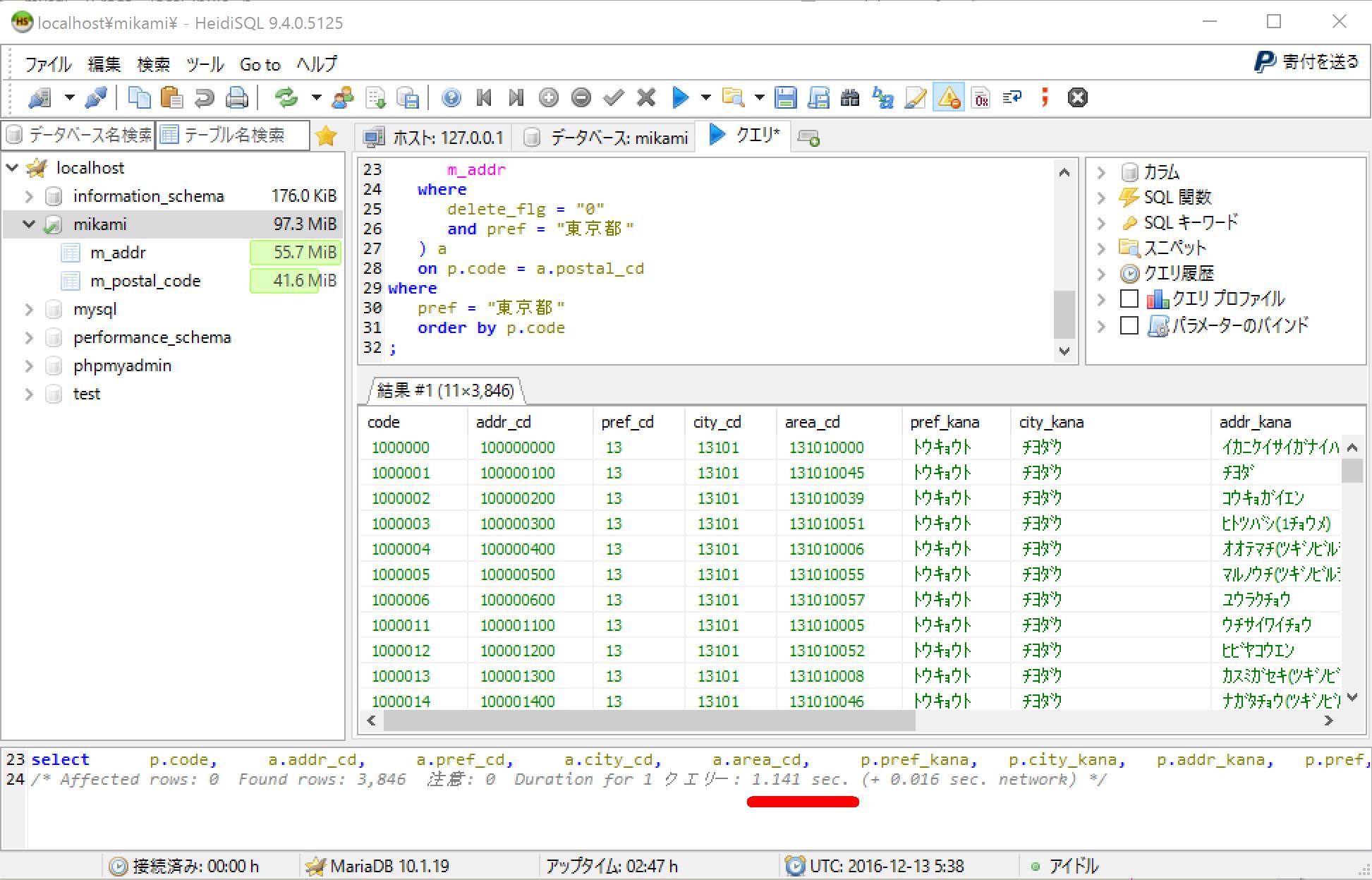
- 実行時間:約1 sec
あ、案外早かった。。(10万件レベルなら、RDS許容範囲ですし、ね。。
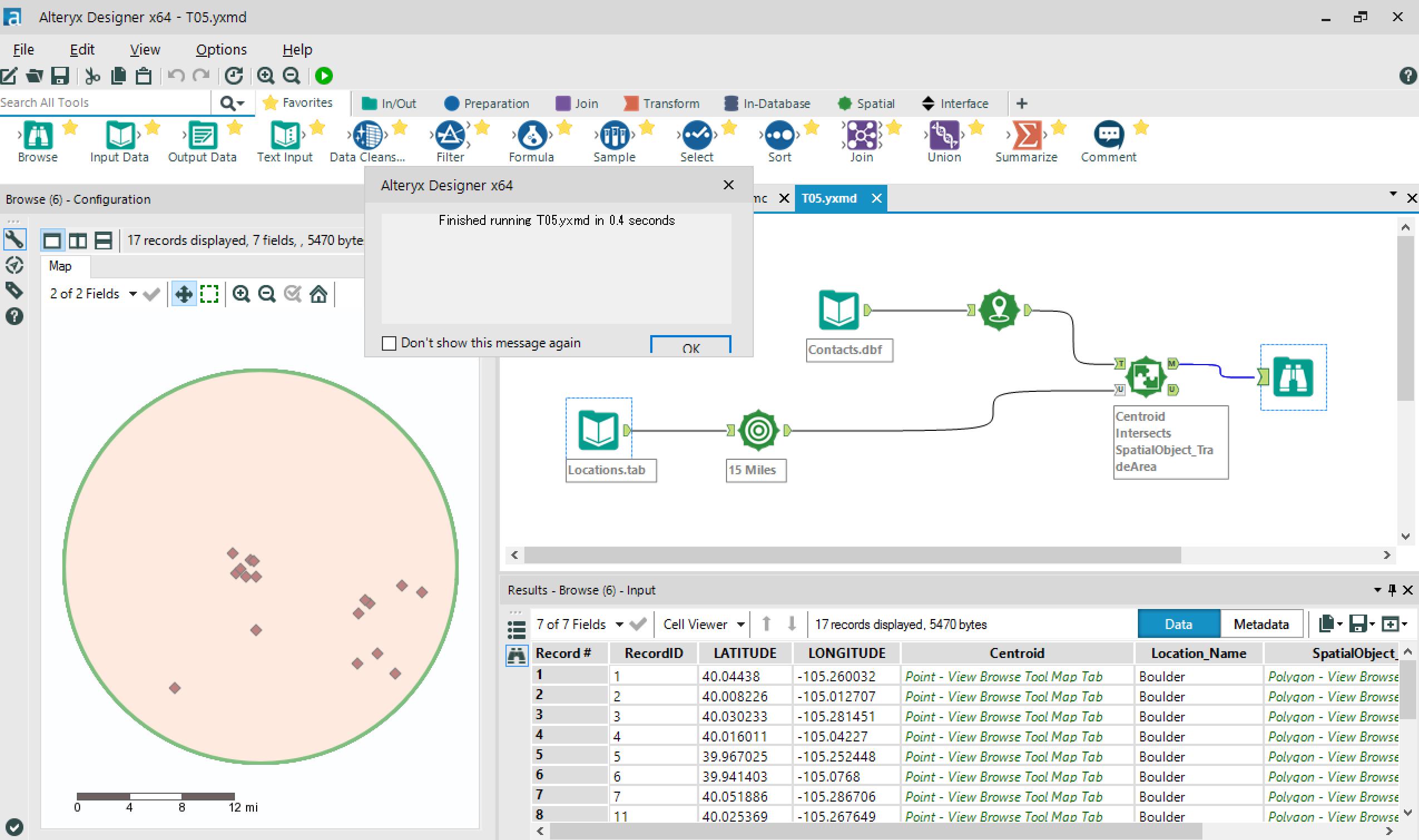
Tutorial 04〜08:データ分析 & GUIやマクロをつくる
Alteryxの本領発揮(?!)
Inputしたデータを分析できます!
ドロップダウンリストやチェックボックスなどのGUIも簡単に追加でき、分析対象を選択できます!
詳しくは、先輩がたのブログでもご紹介中です。
Alteryx Advent Calendar 2016 - Qiita
個人的には、緯度経度データからの位置情報の可視化にちょっと感動v
Tutorial 09:データベース接続
DBからデータを抽出します。
まずは、Redshiftに接続してみます。
全国の郵便番号データを、Redshiftに入れました。
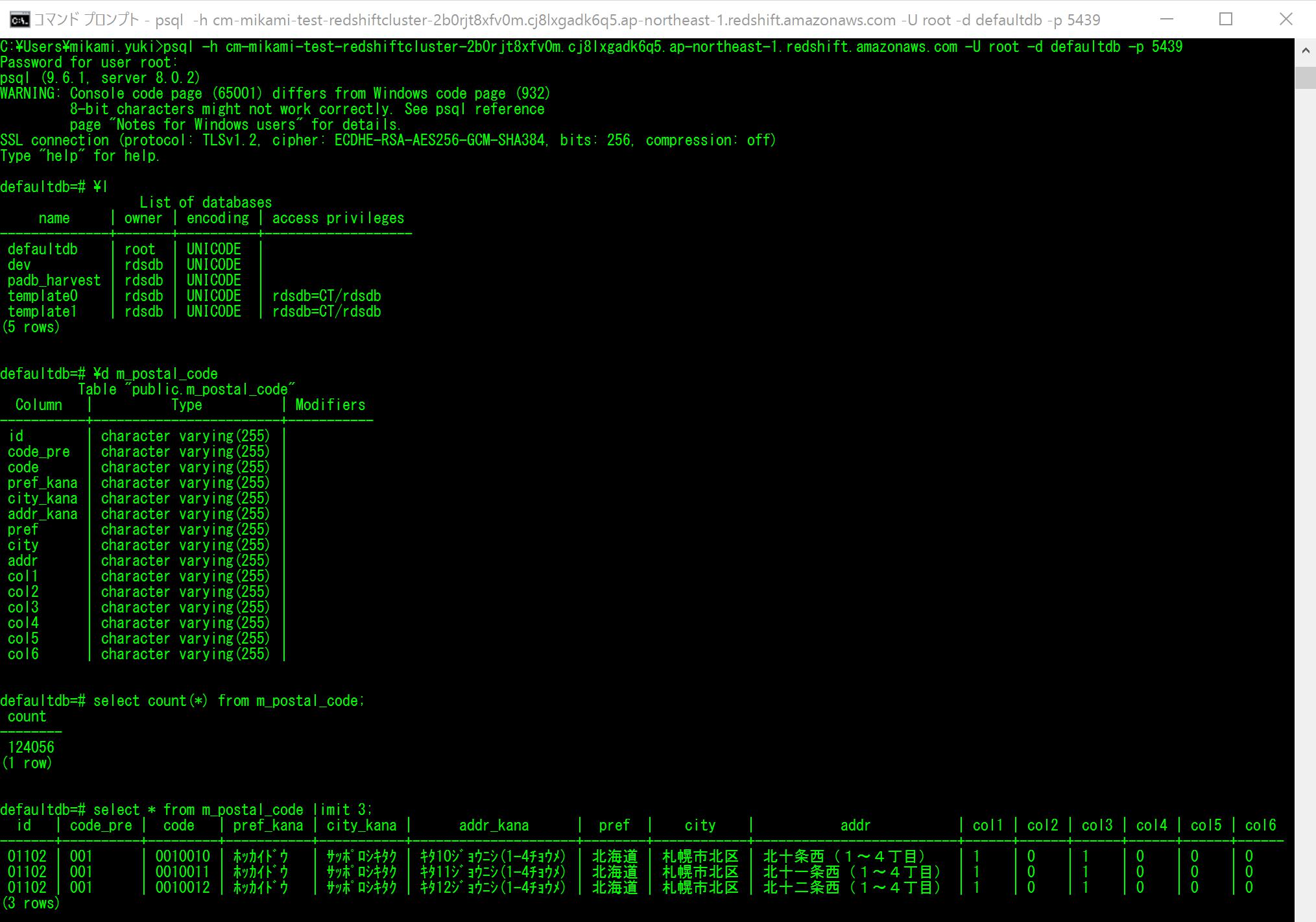
ODBC(Open Database Connectivity)で接続するので、RedshiftのODBCをインストールしておきます。
「In-Database」タブから「Connect In-DB」アイコンを配置して、「Connection Name」プルダウンから「Manage Connections...」をクリック。
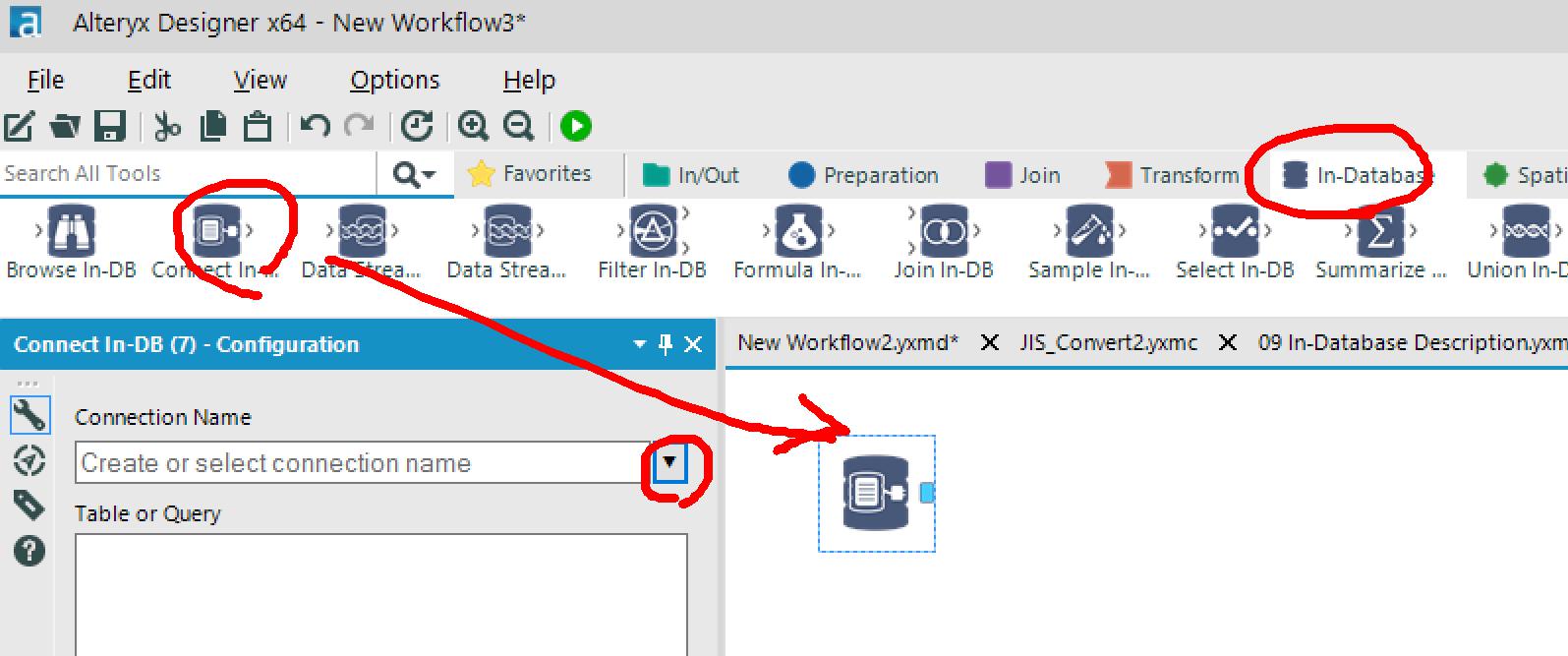
ポップアップ表示されたManage In-DB Connectionsウインドウで以下を設定します。
- 「Data Source」プルダウンから「Amazon Redshift」を選択
- 「Connections」の「New」ボタンをクリック
- 「Connections String」プルダウンで「New database connection...」をクリック
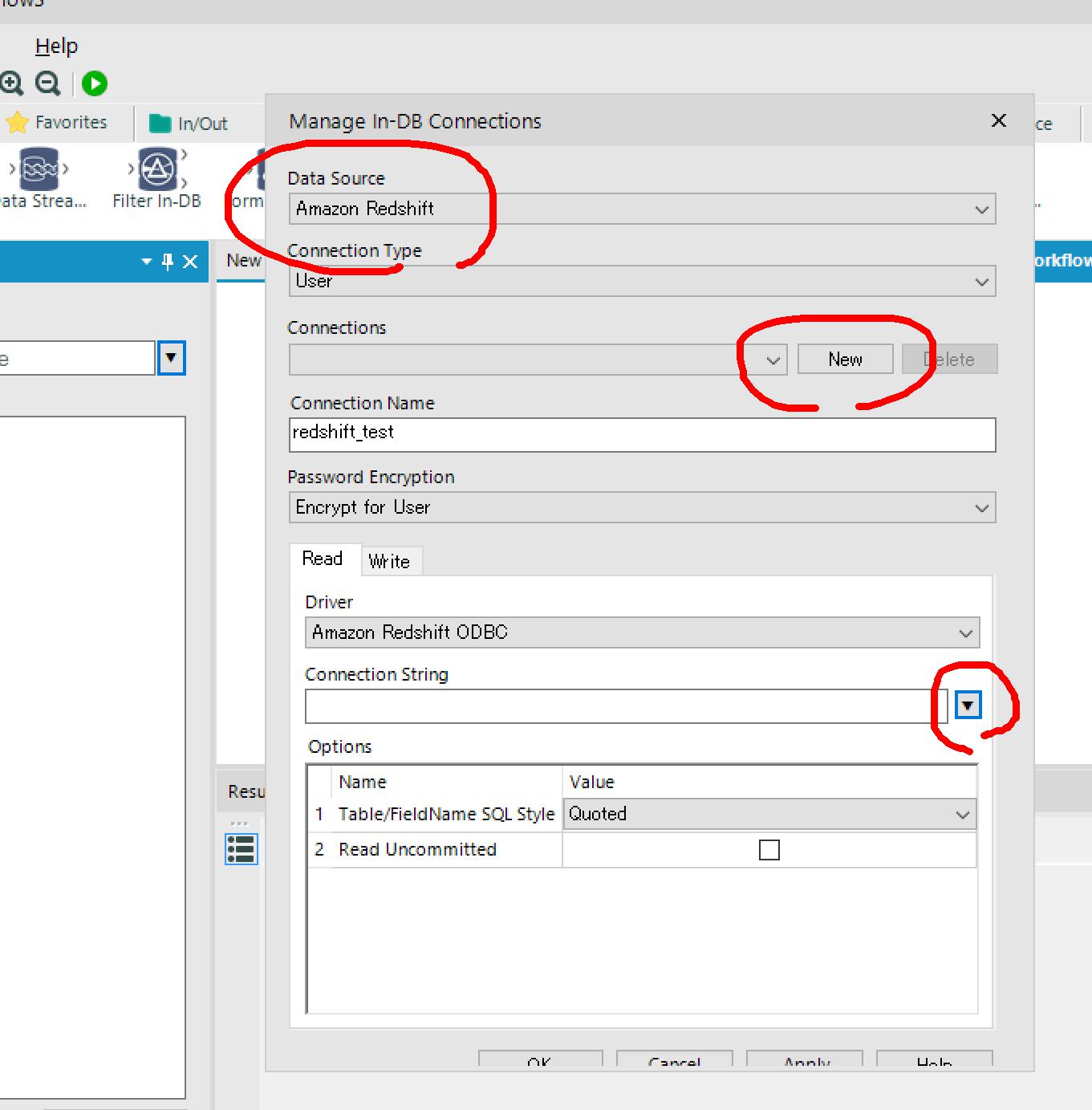
Redshift ODBC Connectionウィンドウがポップアップ表示されるので、「ODBC Admin」ボタンをクリック。
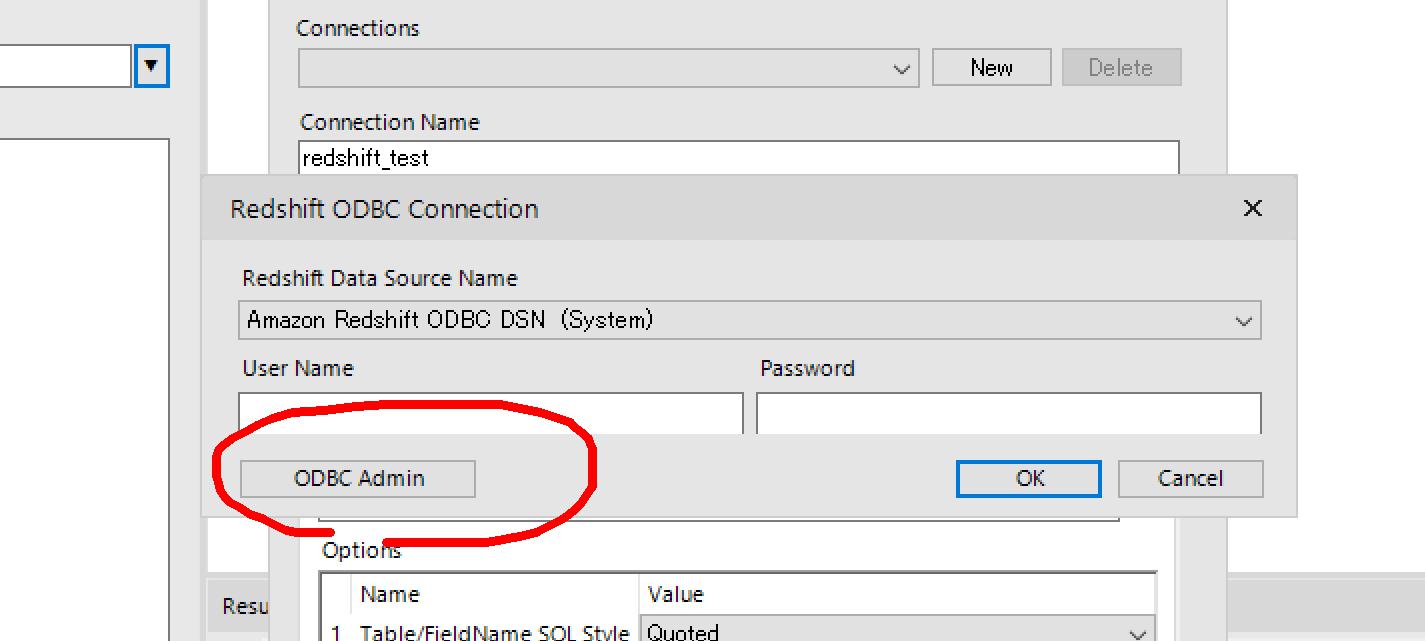
ODBCデータソースアドミニストレーターで「追加」ボタンをクリックし、インストール済みのRedshiftのODBCを選択→「完了」ボタンをクリック。
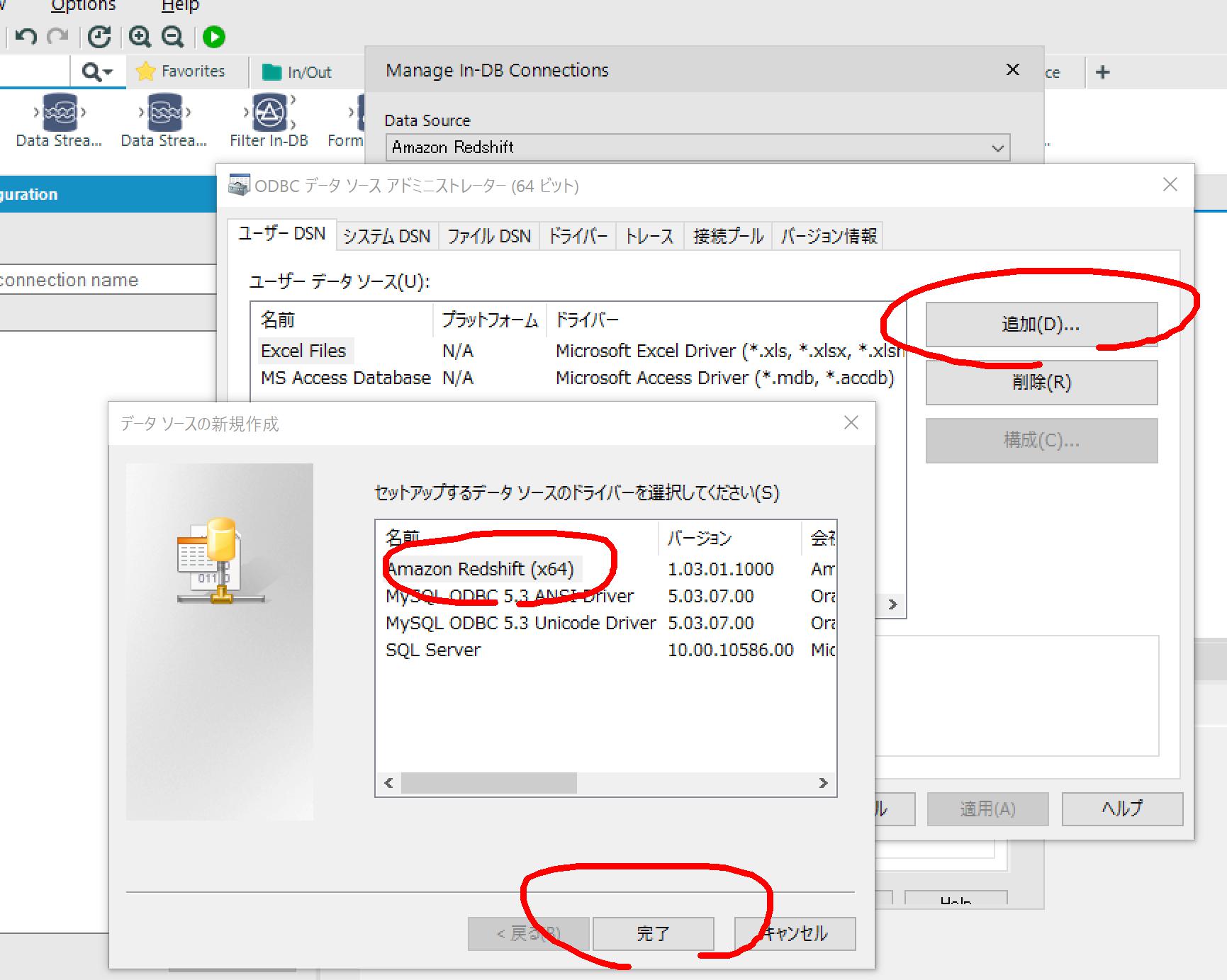
接続先情報を入力して「OK」ボタンをクリック
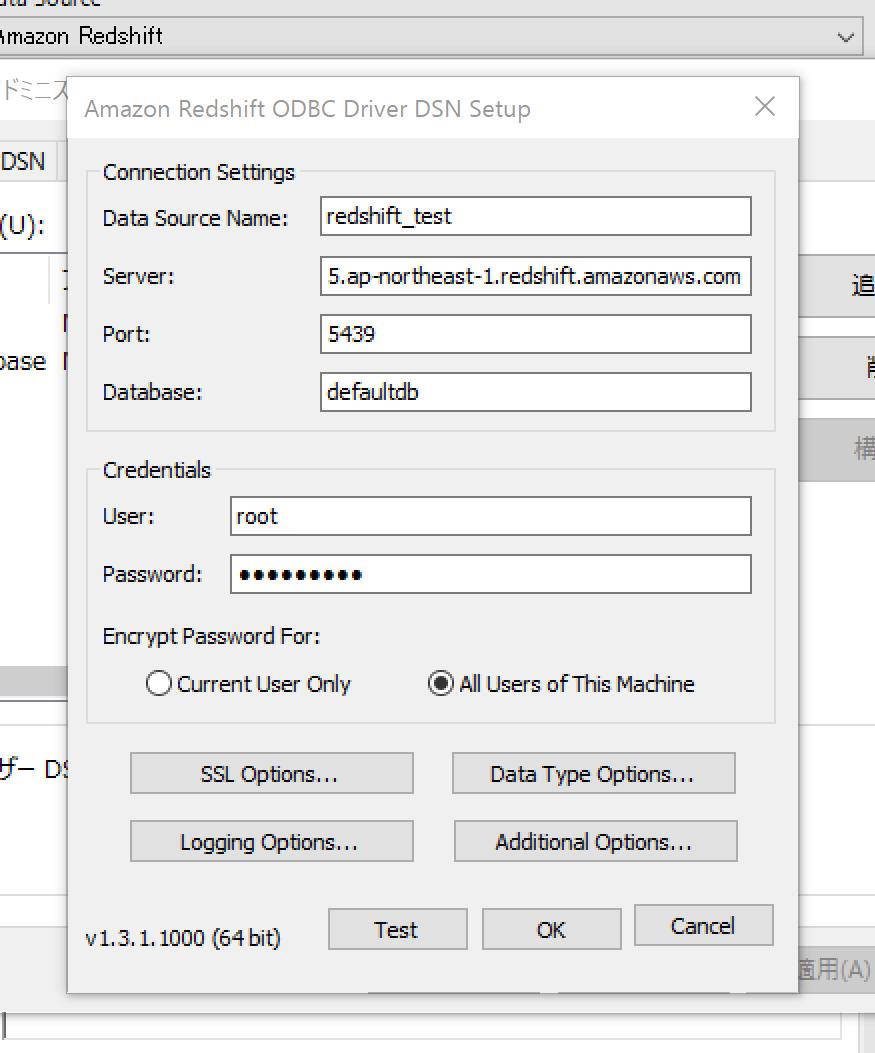
追加したデータソースを選択して「OK」ボタンで戻ります。
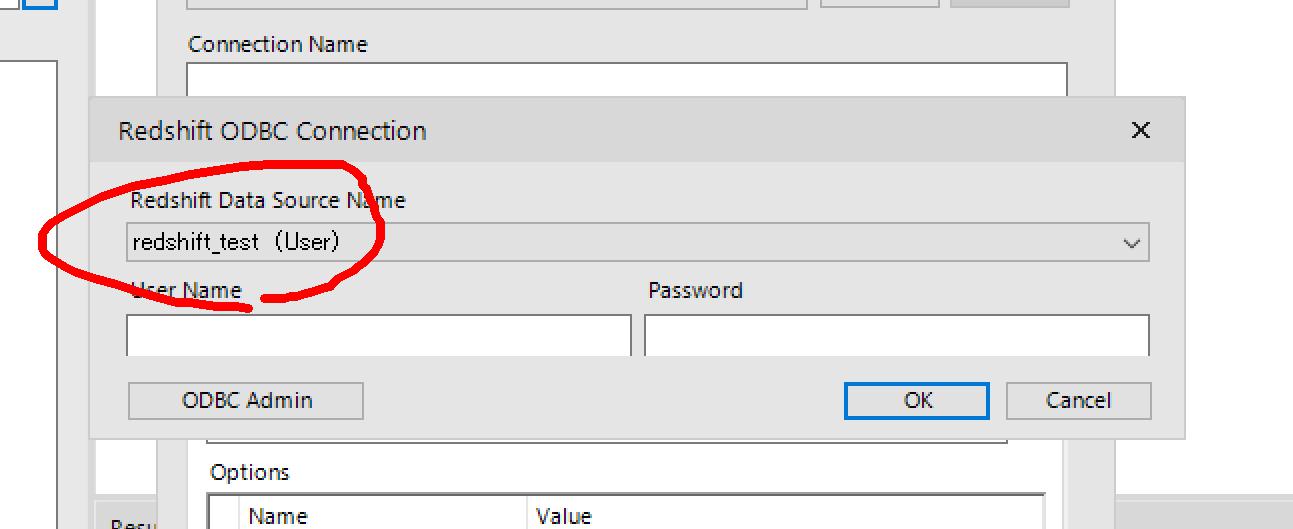
Redshift ODBC Connectionウィンドウの「Redshift Data Source Name」プルダウンにデータソースが追加されているので、選択してOK。
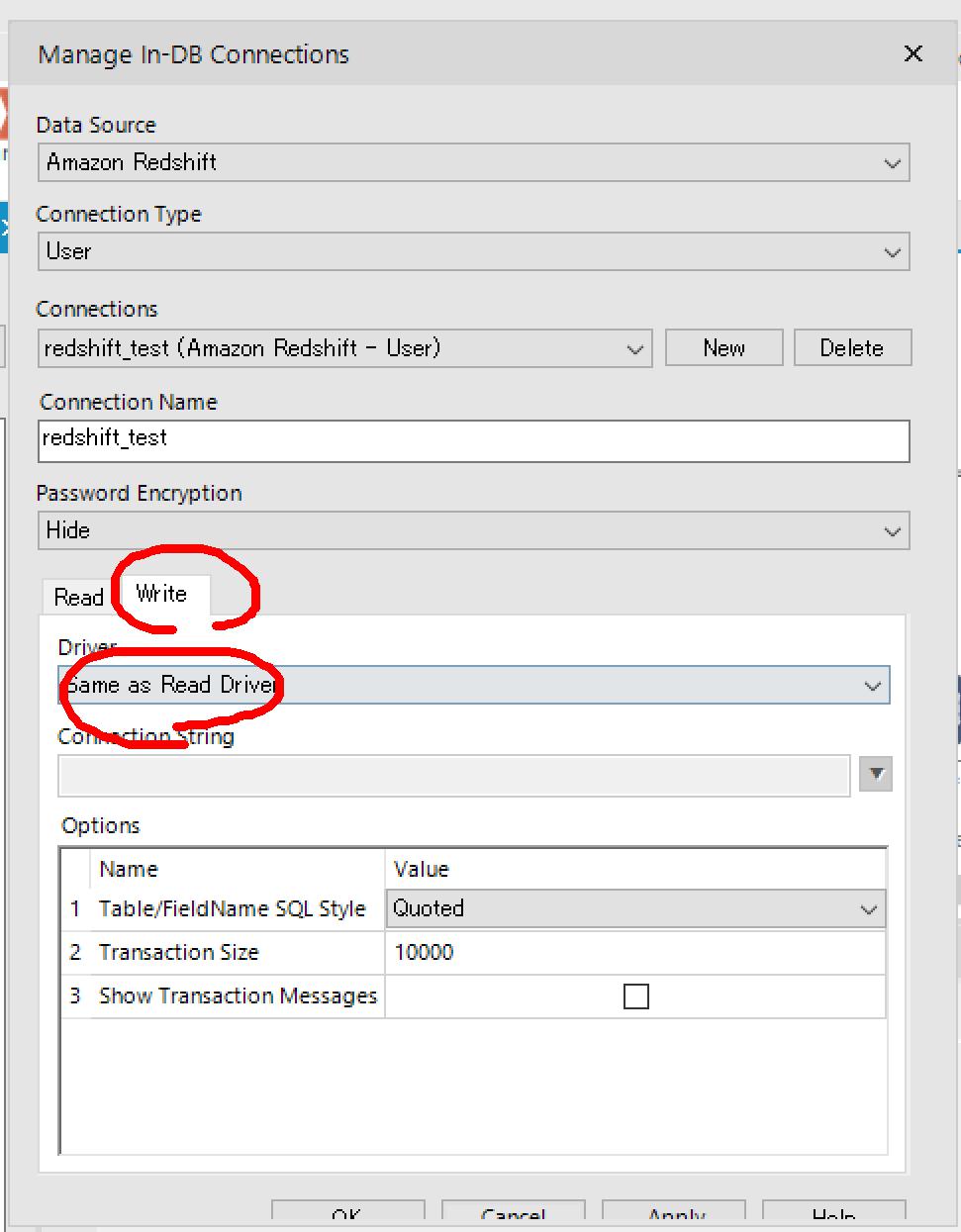
Manage In-DB Connectionsウインドウの「Write」タブの「Driver」でも「Same as Read Driver」を選択しておきます。
Choose Table or Specify Queryウィンドウが表示されるので、テーブルを選択(またはクエリを入力)してOK。
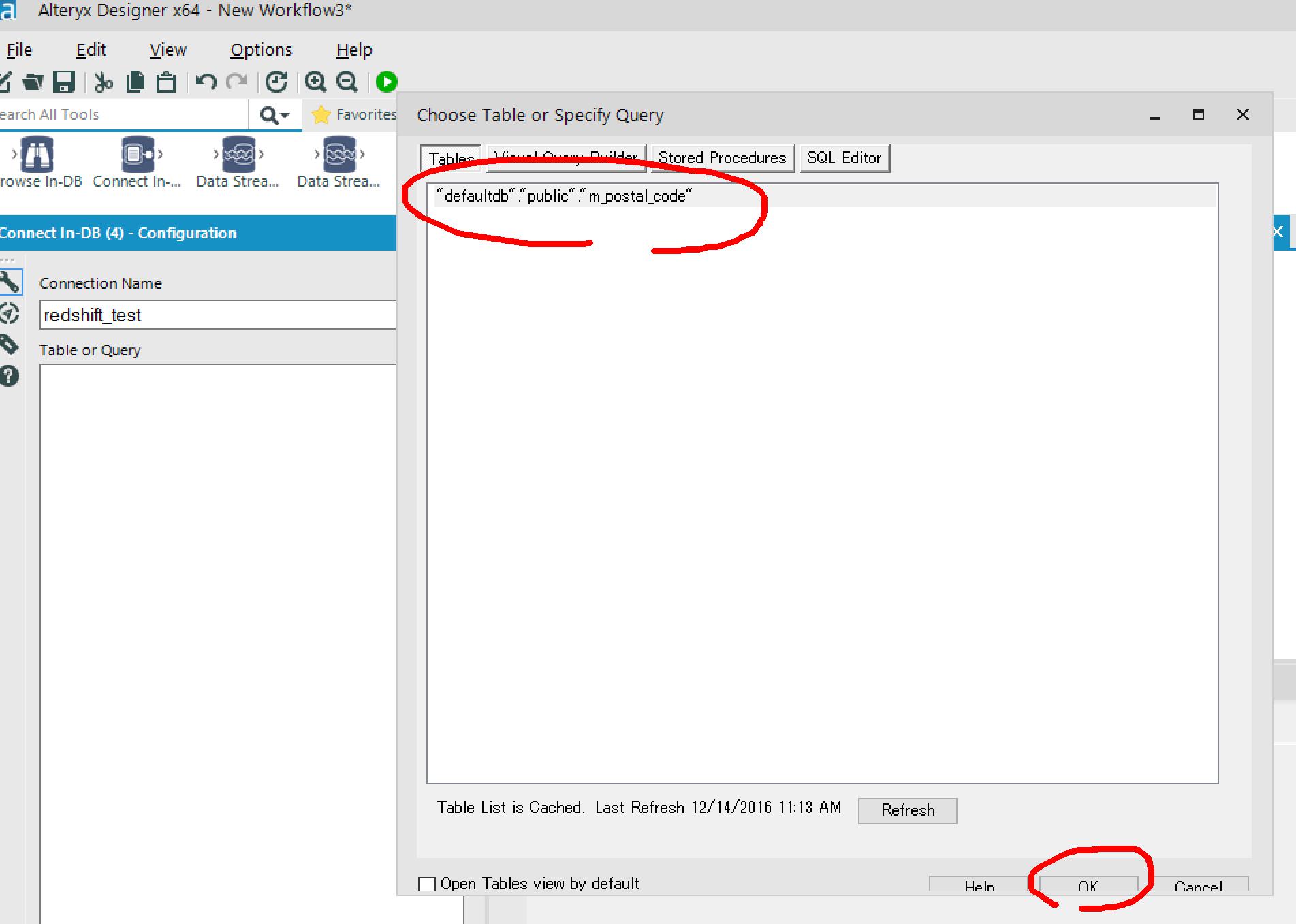
Browsw In-DBをつないで実行してみると、
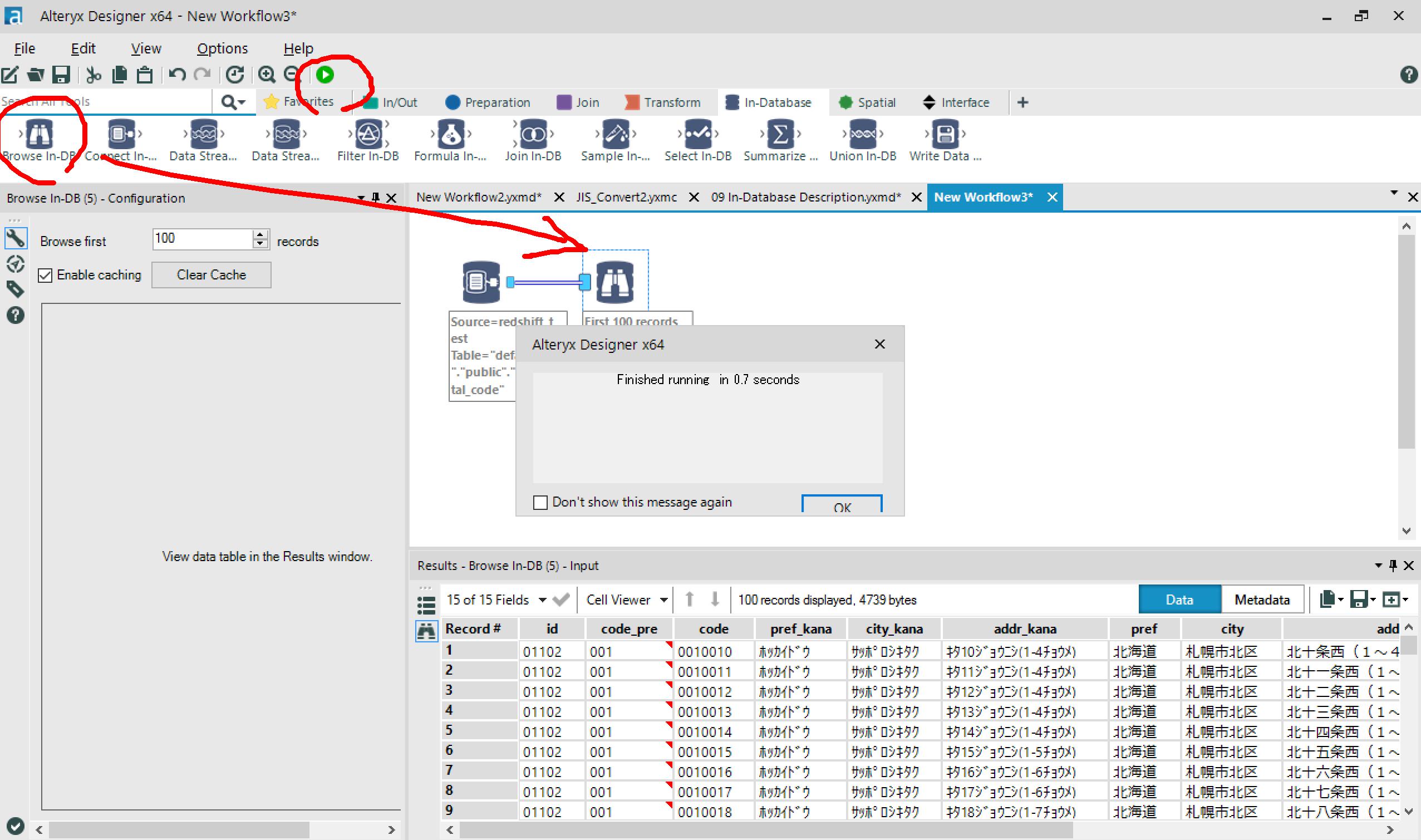
Redshiftのデータが取得できました!
→Filter In-DBで、東京都のレコードだけ抽出します。
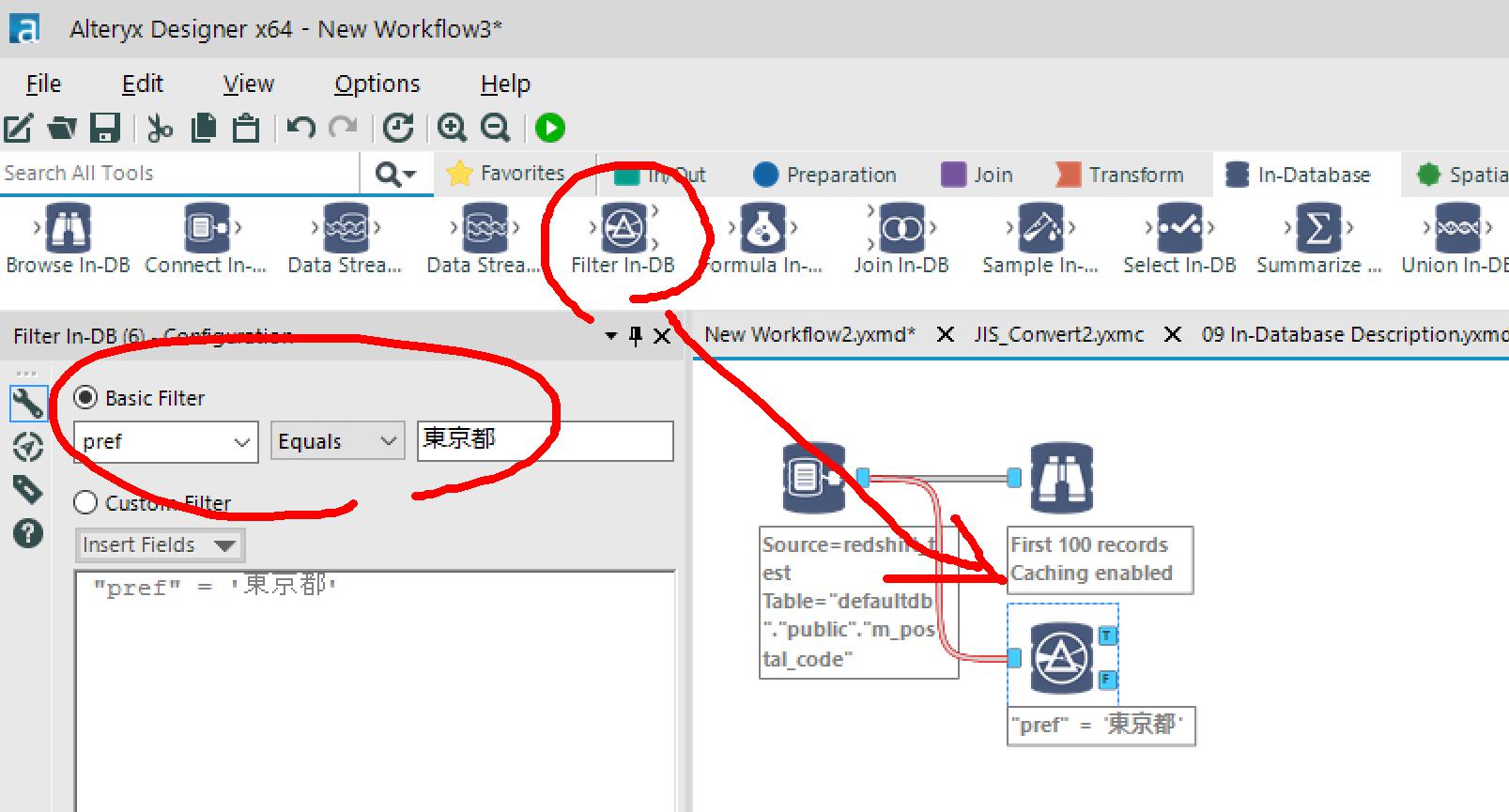
これにcsvファイルから住所データをブレンディングしてみます。
csvからInputのワークフローを作成したら、Data Stream Inをつなげて、Inする先を設定。
今回はRedshiftのtest_alteryxテーブルに上書きで入れますが、データソースは変更可能でテンポラリテーブル指定もできます。
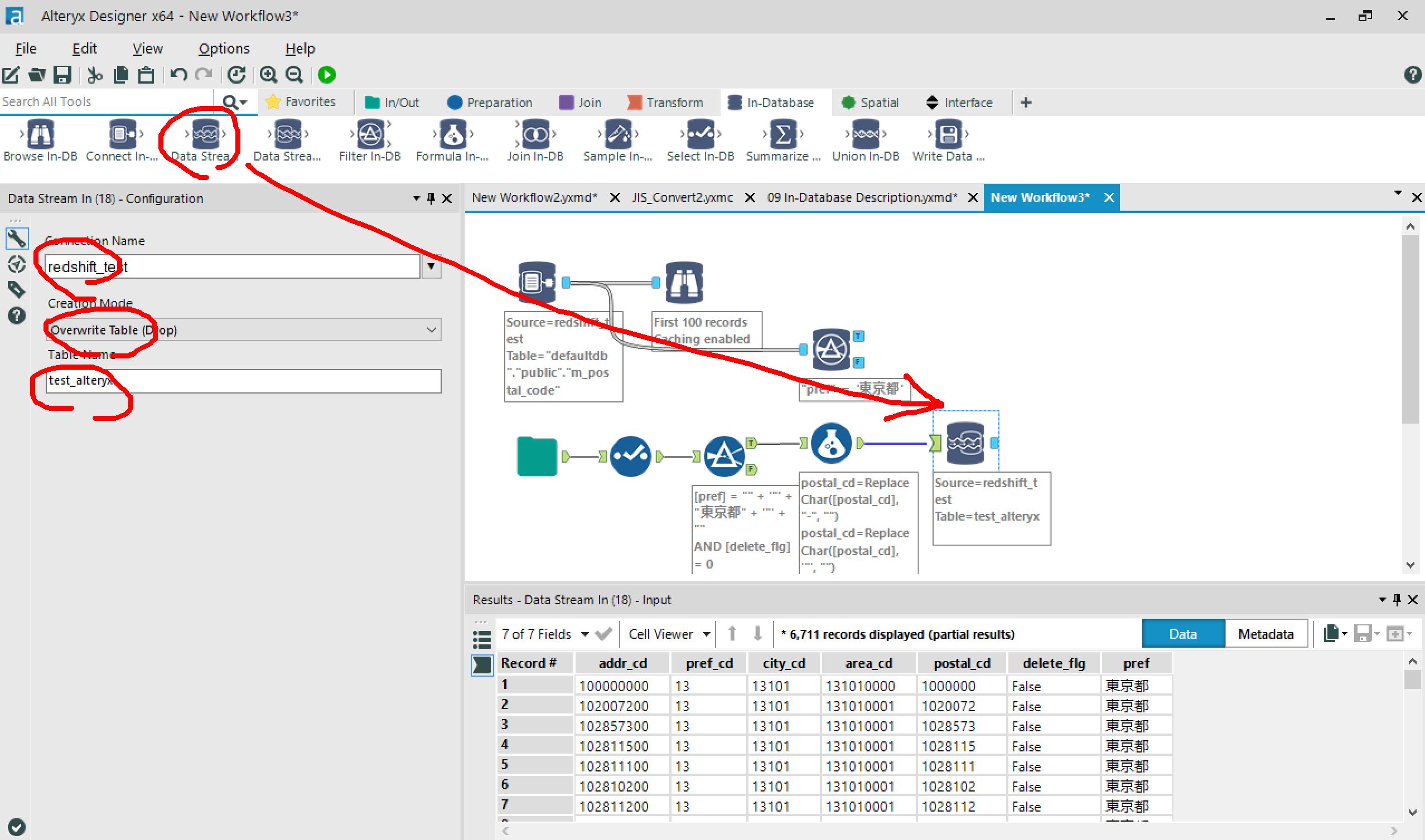
ワークフロー実行時、ここで指定した先にちゃんとデータがInsertされていました。
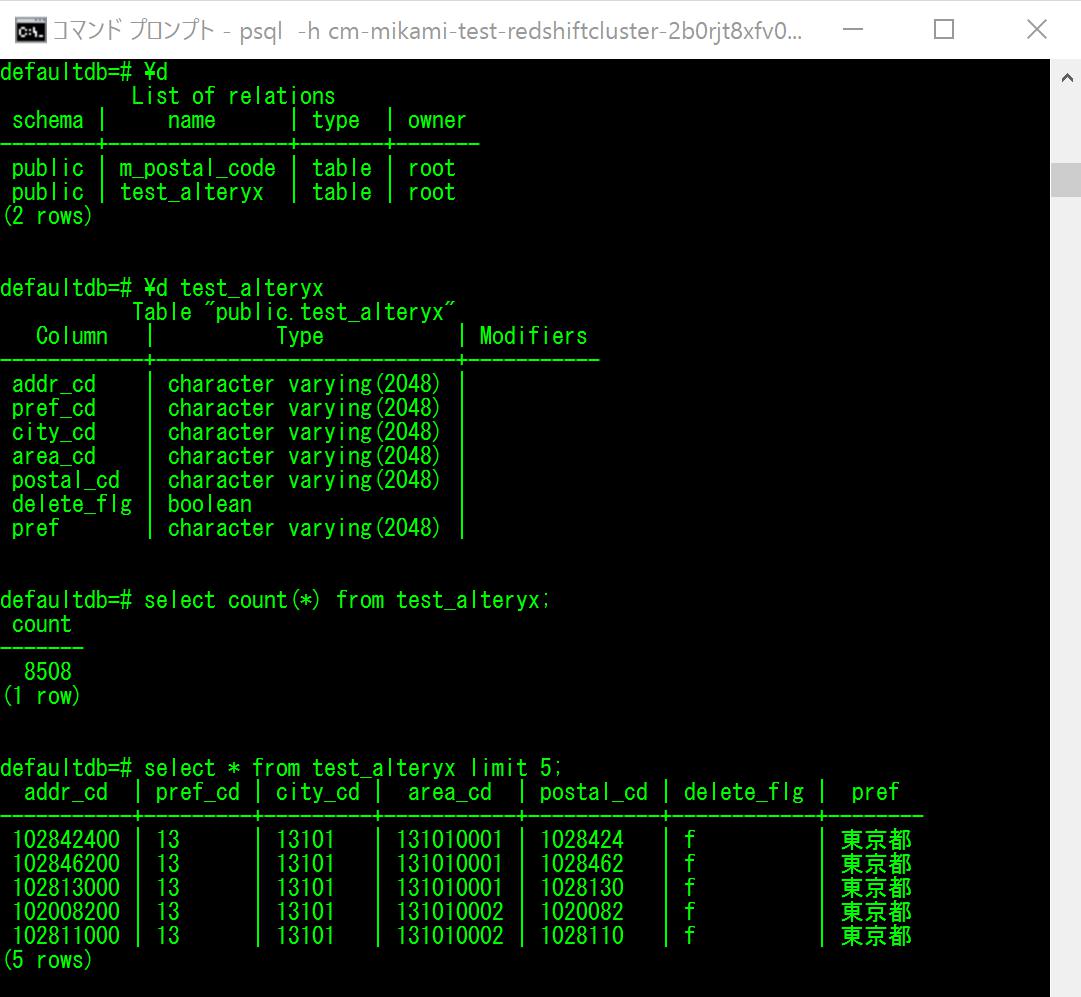
→Inner Joinで結合条件を指定します。
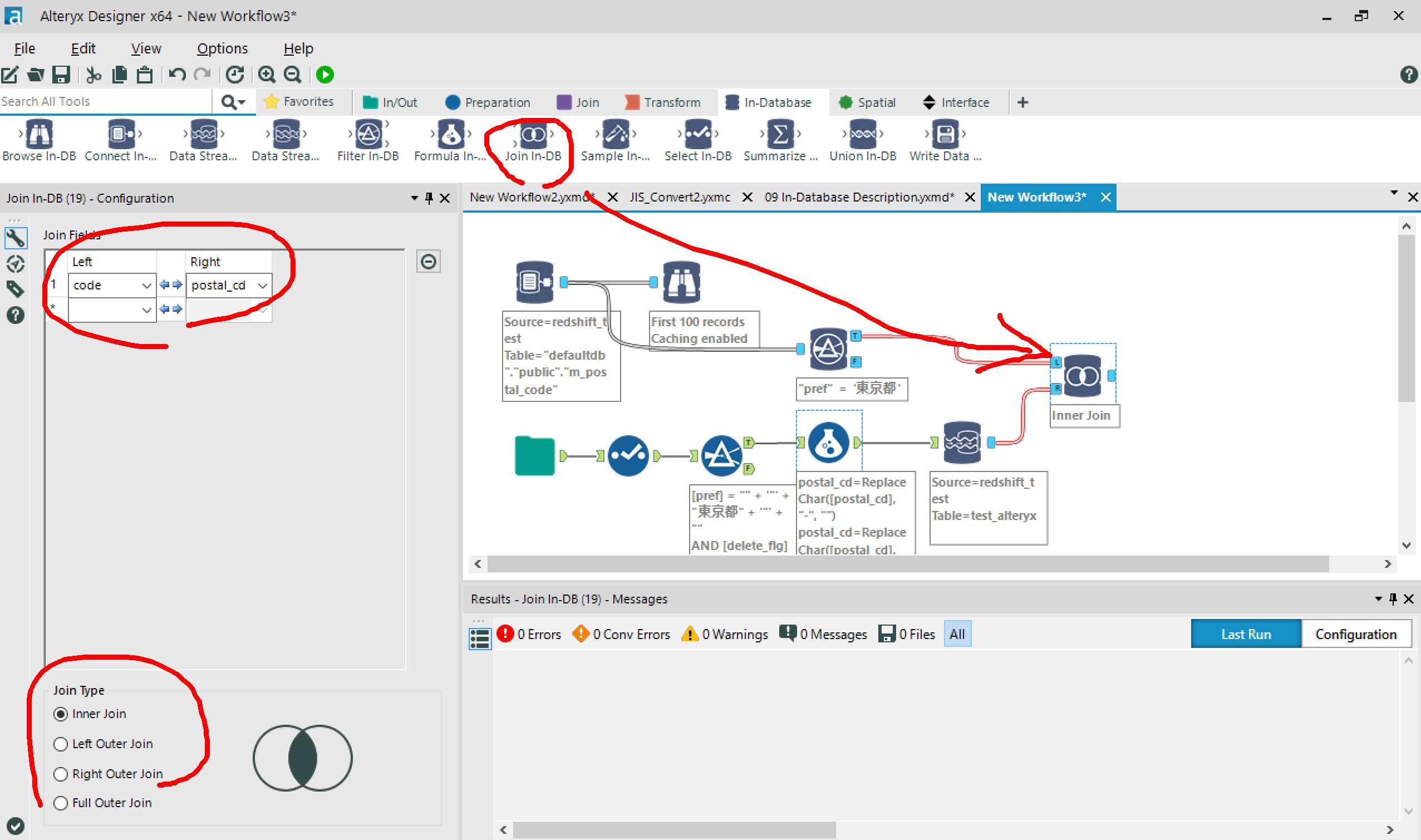
その先にData Stream Outをつなげれば、またAlteryx上でデータの分析や整形ができます。
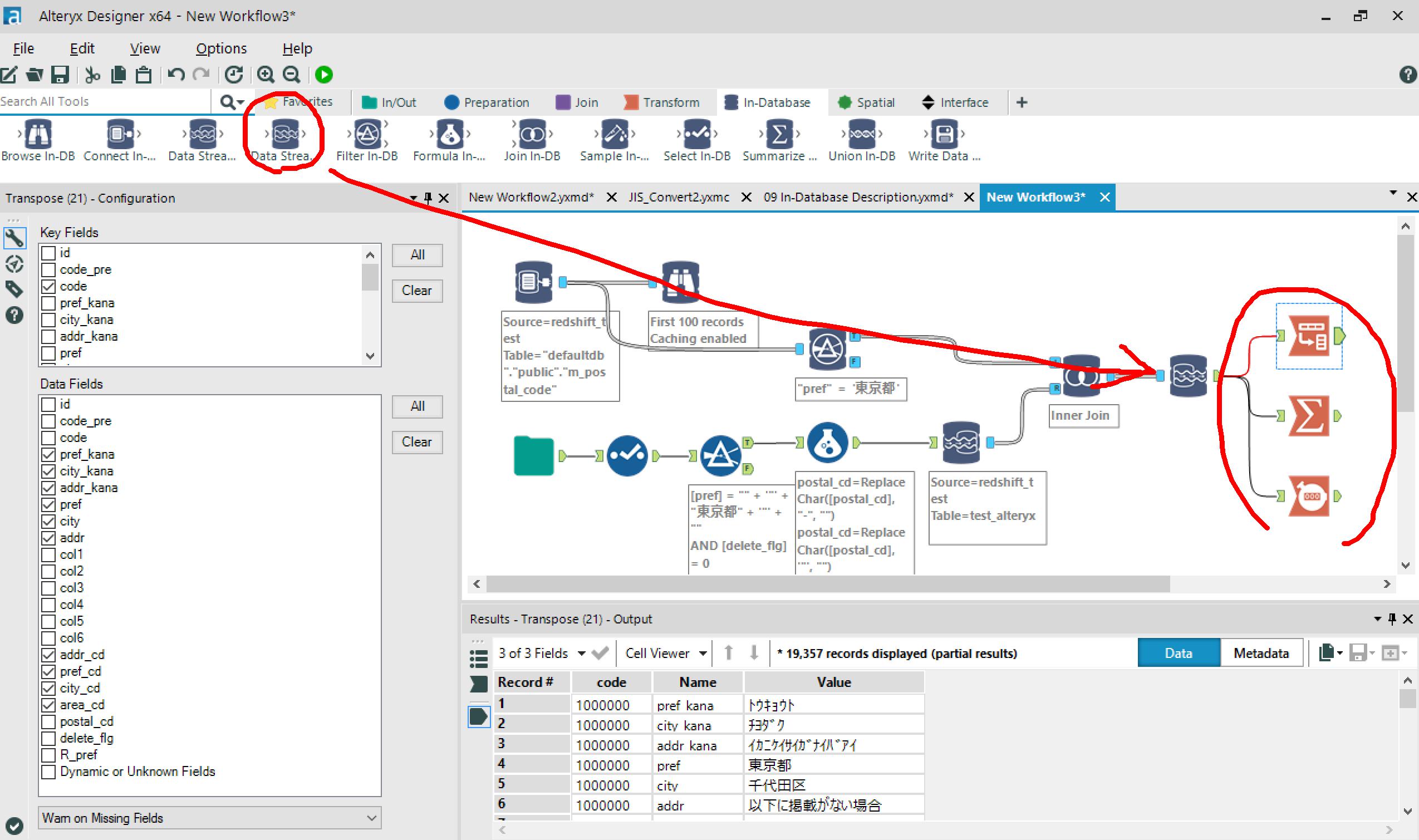
ちなみに・・
Redshiftのデータを先にStream Outしてからの結合も、もちろん可能。
Redshiftに一回データを入れて → また出して、の手間がない分、実行時間も随分違いました。
※前者:約3min / 後者:約8sec
- outer joinで結合したい
- サマリー結果をDBに残したい
などの場合は前者のフローにすべきかと思いますが、用途に合わせてワークフローも自由に作成可能です。
まとめ(所感)
- 感覚的に簡単に操作できました。
- ワークフローが可視化され、実行中のプログレス表示もあるので、わかりやすかったです。
- ツール(できること)が多い!(嬉しいやら、混乱するやら。。@@;
- ツールによっては指定条件の型制限(先に型を変更しなければならない)などあるため、慣れるまでは大変。。
- 公式がまだ英語だけなので、日本語ヘルプが(ごにょごにょ。。
→当ブログでも今後もAlteryx関連ドキュメント、充実させてまいります!
明日16日目はtruestarさんの『Alteryxで調査データをTableau用データに加工してみた』の予定です。
明日もお楽しみに!









